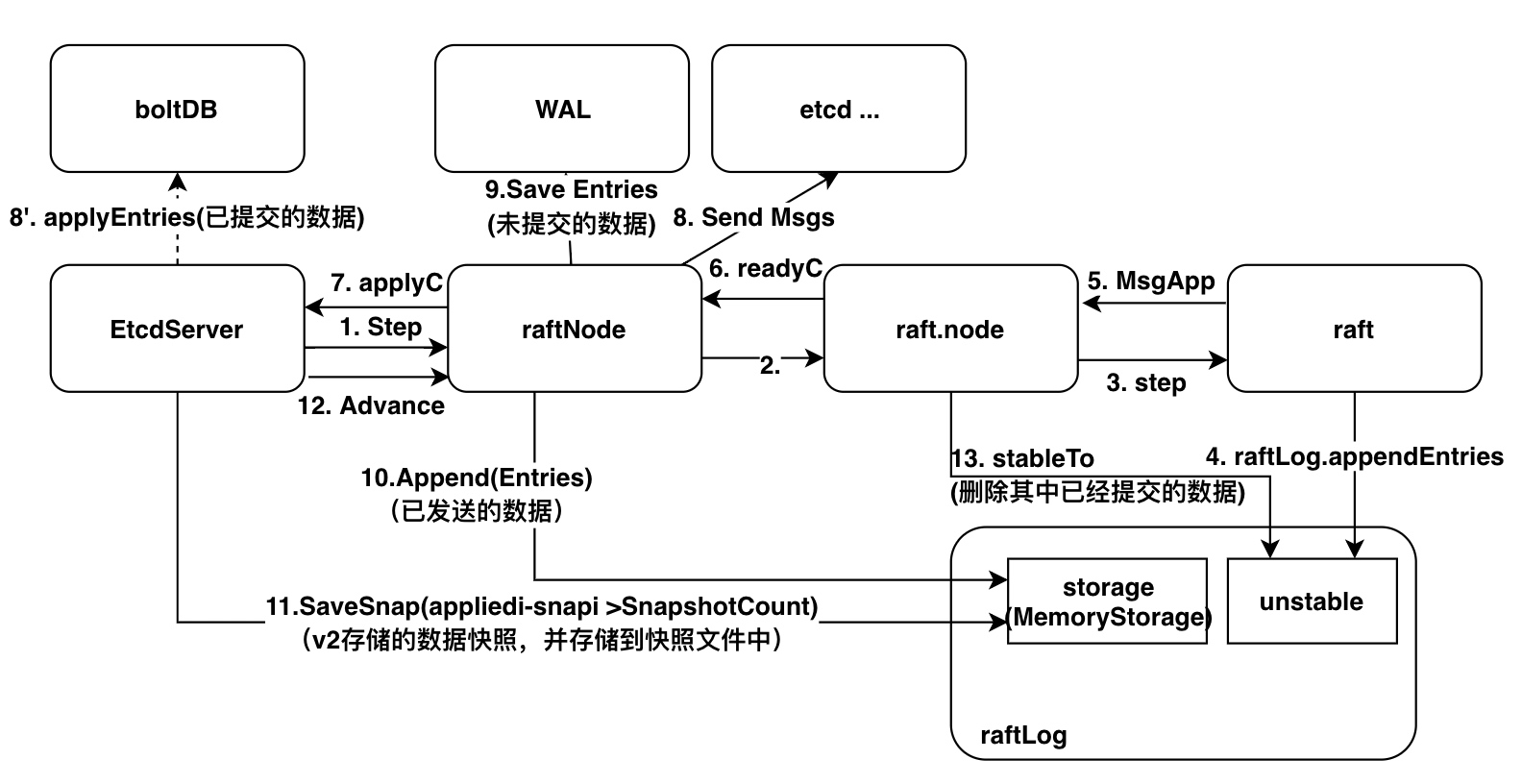
6. Watch机制
watch用于监听指定key或指定key前缀的键值对的变动。其 api 如下:
1 | etcdctl watch --prefix[=false] // 带前缀 |
下面将详细解析其工作原理。首先将介绍其初始化过程,其次介绍创建watch过程以及相关键值对修改时的操作。
6.1 初始化过程
在初始化存储的时候,提到了newWatchableStore方法,其对boltDB进行了一次封装。
1 | s := &watchableStore{ |
首先来看下WatcherGroup的数据结构:
1 | type watcherGroup struct { |
总结整体流程如下: