3. 数据存储
Etcd的存储部分,可以分两部分来讲解。一部分是其应用层的数据存储方式,另一部分是raft相关数据的存储。Etcd应用层的数据存储从v3版本开始就延用boltDB,其也是CoreOS的产品boltDB。PS:本文主要聚焦于v3版本,对于v2版本不作解读。
下面将分别介绍这两部分内容:
3.1 raft数据存储
首先我们来介绍下raft相关的数据存储:raft中有两个比较重要的组件:
raftLog:用来保存状态机相关信息的,包括当前任期、索引号、不稳定记录项等;WAL:预写日志器,用于以顺序形式写入操作记录,以便故障时数据恢复;Snapshot:数据快照,一般用于启动时快速恢复数据。
首先来看raftLog:
1 | type raftLog struct { |
下图描述了数据从客户端请求到落地各个阶段与以前存储结构的关系: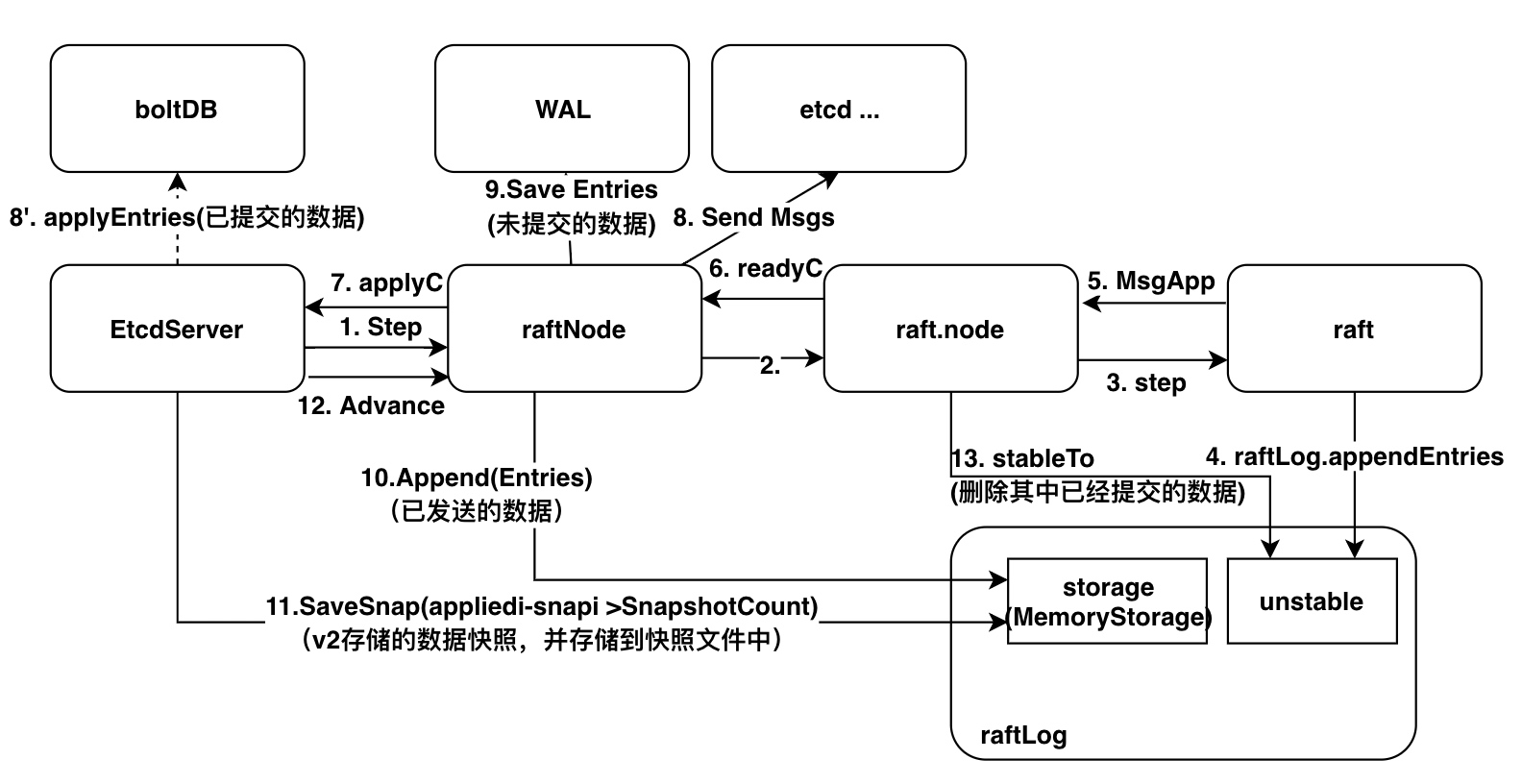
其中,8’、9、11 是涉及 I/O 的操作,其他均为内存操作。
对WAL的操作在每次写事务操作中都会存在,因此其是制约etcd写性能的一个重要因素。接下来,将重点介绍WAL的工作原理。
1 | type WAL struct { |
首先,来看其创建过程:
1 | wal.Create |
创建WAL时,会初始化编码器以及FilePipeline。下面再以其Save方法来介绍保存记录的过程:
1 | WAL.Save |
随着记录的增加,wal文件会越来越多,入股不做处理的话会导致磁盘被占满。那么etcd是怎么做的呢?
其实是由两步构成的:
- 当
etcd每次进行执行快照的实时,会进行wal.ReleaseLockTo(snap.Metadata.Index)释放文件锁的操作。(释放快照对应索引号之前的所有WAL文件句柄) - 之前在
EtcdServer启动章节介绍过,其启动后会启动一个定时任务purgeFile。其会针对snap.db、snap、wal文件做30秒一次的fileutil.PurgeFile任务:- 任务带有参数
MaxWalFiles,获取指定wal.dir下所有文件,然后按文件名排序,从小到大进行遍历:尝试锁文件。如果成功,则进行删除,否则的话说明依然被etcd锁占用。
- 任务带有参数
3.2 应用数据存储
在解析etcd应用层数据存储结构前,先来介绍下etcd的数据存储形式。etcd对数据的存储并不是直接存储key-value对,而是引入了一种带版本号revision的存储方式:以数据的revison为key,键值对为值。revision由两部分组成:main-revision.sub-revision。main-revision为事务ID,sub-revision为事务中一次操作ID。
举例来说:
系统刚启动后,在一个事务中执行put ty dj \n put dj ty两个操作,实际存储的是
- {1,0} key=ty val=dj
- {1,1} key=dj val=ty
紧接着执行第二次操作:put ty dj90 \n put dj ty92,那么存储中会追加如下信息:
- {2,0} key=ty val=dj90
- {2,1} key=dj val=ty92
而为了支持这种存储形式快速查询,etcd建立了treeIndex结构,用于建立key与revision间的关系。随之,通过key查询val的过程如下:
treeIndex是一个b-ree,其存储这keyIndex信息。KeyIndex的结构如下:
1 | key []byte |
keyIndex中,需要特别说明的是generation数据内部,保存的revs,如果最后一项为tombstone,则表示在这个代中被删除了。被tombstone的generation是可以被删除的。针对此,keyIndex有个专门的函数compact,compact(n)可以将主版本小于n的数据。
将完了其存储结构和存储格式,下面将从启动和执行一次操作两个流程来讲解其的工作原理。对boltDB不了解的读者建议先去了解下 boltDB、boltDB学习。
3.2.1 启动过程
etcd应用层存储创建过程如下:
首先创建backend,其是对boltDB的封装,加入一些批量提交逻辑。
1 | bepath := cfg.backendPath() |
有了backend后,会再基于此作一层封装:mvcc.New(srv.getLogger(), srv.be, srv.lessor, &srv.consistIndex),其内部包含watcher处理机制:
1 | mvcc.New |
这里我们比较关注的是NewStore逻辑:
1 | mvcc.NewStore |
由此就完成了treeIndex和boltDB的初始化。
最后,etcd又对mvcc.watchableStore进行了一次封装srv.newApplierV3Backend(),其用于衔接存储和raft消息请求。
3.2.2 请求应用到存储
put ty dj请求通过raft协议提交决策后,最终会调用到applierV3backend.put方法进行应用:
1 | applierV3backend.put |
到此就完成了存储模块的讲解。

