1. Etcd冷启动
1.1 初始化主流程
Etcd的启动类为 父目录的main.go文件。其启动过程调用如下:
1 | main.go |
startEtcd中执行etcd启动的主要过程:
1 | embed.startEtcd(inCfg *Config) |
通过 cfg.PeerURLsMapAndToken(“etcd”) 逻辑,了解到etcd有三种方式来获取集群中其他节点信息:
1 | switch { |
准备好创建etcd节点后开始初始化节点信息:
1 | etcdserver/NewServer(srvcfg) |
初始化快照管理器和数据库后端后,就会根据一系列条件来决定怎样启动节点:
1 | switch { |
创建完raft.Node并绑定相应raft后,继续初始化:
1 | |- stats.NewServerStats // 初始化统计计数 |
下面来看raftNode的详细创建过程:
1 | newRaftNode( |
可以看出raftNode和raft.node之间的关系。通过raftNode可以直接访问raft.node的所有公有方法。
回到 startNode 方法,我们以新集群且没有WAL文件的场景来了解下startNode的处理过程:
1 | etcdserver/raft.go/startNode |
下面我们来详细了解下newRaft的内容:
1 | newRaft(c *Config) *raft |
接下来,再来看 becomeFollower 方法,其设置了 step 方法和 tick 方法、设置了 raft所在任期以及raft的角色状态。我们都知道raft协议中共有三个角色Follower、Candidates、Leader。etcd中通过不同角色设置不同的step来区分开每个角色的处理逻辑,设置不同tick方法来设置超时任务(对于Follower角色,其超时后会发起新一轮选举,而对于Leader角色,则广播一次心跳消息… )
1 | func (r *raft) becomeFollower(term uint64, lead uint64) { |
到此,就完成了 EtcdServer的创建。
接下来,再来看EtcdServer的开始方法Start:
1 | EtcdServer/Start |
EtcdServer.start()方法,首先进行一系列通道的初始化,然后异步执行EtcdServer.run()方法:
1 | EtcdServer.run |
展开 raftNode.start(rh)的逻辑如下:
1 | select { |
完成etcdServer的启动后,开始http/grpc服务对外提供服务(peer间的服务以及对client开放的服务)。
我们以servePeers()来讲解启动服务过程。
1 | servePeers() |
当新连接到达时,处理流程如下:
1 | cMux.Server() |
到此整个初始化过程就完成了。其后开始进行选举,那么选举是哪里出发的呢?
1.2 选举
回到创建raftNode的地方 r.ticker = time.NewTicker(r.heartbeat) 开启了ticker。当时间到达时,tickder.C中得到通知。而其正在被 raftNode的start方法中的循环监听着。进一步就触发了raftNoe.tick()方法。
1 | raftNoe.tick() |
当其他接收到该节点的投票请求时:
1 | peer.go/startPeer(180L) |
当节点收到 其他的投票反馈消息时,最终会调用 raft.go/stepCandidate方法。
1 | // poll方法传进去本消息的投票,返回已经有多少赞成票 |
通过上面的逻辑,可以看出,当投票数达到quorum数时,转变角色为主节点。同时向所有其他节点广播本节点状态以及记录信息(MsgApp),其他节点接收到此消息后,自动转变为 follower角色,整个集群初始化完成。
总结选举过程如下:
- 每个节点启动时作为
Follwer角色,经过一个ElectionTimeout(启动时随时生成的默认150ms~250ms)后进入Candidate状态,并向其他节点发送消息MsgVote消息(本节点的Term、最新的日志Index,最新日志的LogTerm); - 其他节点收到投标后,进行两步判断:
- 预判断,:
r.Vote==m.Form(是否已经投标给该节点)- 当前节点未投标且无leader节点;
- 对于预投标(
PreVote),消息的任期比当前节点大;
- 任何一个条件判断则可以进入正式判断:
- 若消息中
日志Term对当前节点大则投给消息发送方,若日志Term相等,Index比当前节点大则也将票投给消息发送方r.raftLog.isUpToDate(m.Index, m.LogTerm)
- 若消息中
- 若上面的判断失败,则返回拒绝
- 预判断,:
- 当发起投标方收到半数以上的头条,则转换自己的角色
becomeLader(raft.go/stepCandidate),并广播一条空消息给其他所有节点。
对于etcd的选举,还需要说明的是,etcd为了解决网络分区的情况下某些节点不停加入集群导致抖动的情况,设置PreVote流程(只需要启动节点的时候 设置 pre-vote 参数)。即在进行真正的选举之前 先进行PreVote得到大多数节点同意选举之后才进行真正的选举。可以解决如下问题:
- 对于网络分区的节点,在重新加入集群的时候不会中断集群;(因为获取不了大部分节点的许可,索引其
Term无法增大,所以赢不了选举主节点)。
到此,etcd的启动到建立集群、完成选举的整个过程就介绍完了。
附加图:
下图为 EtcdServer、raftNode、raft.node、raft间的联系。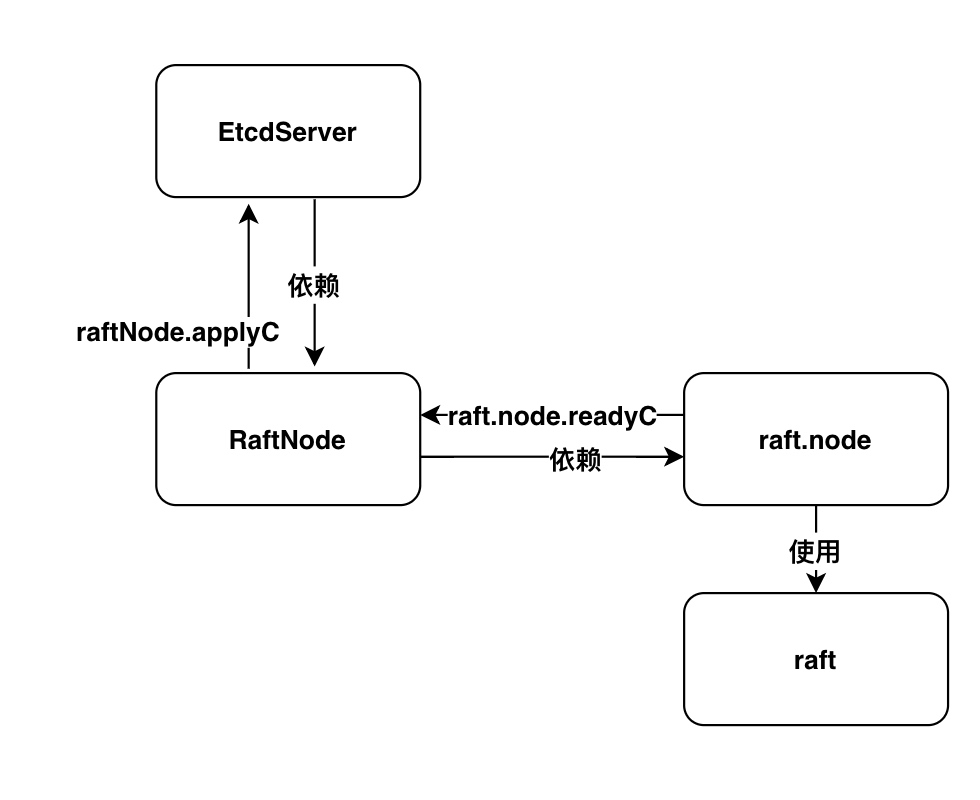
最后补充说明下etcd的proxy模式:etcd可以通过命令./etcd –proxy on –listen-client-urls的形式启动代理模式。代理模式下,它的作用是一个反向代理,接收客户端请求,然后转发到etcd集群。
代理模式有2种运行形式:readwrite和readonly,默认情况下为readwrite,即会将读写请求都进行转发,而readonly形式下,则只转发读请求,写请求将报5xx错误,
IDEA中启动ETCD方式:
1 | debug方式运行三个终端程序 `etcd/main.go` 并设置如下参数: |

