4.kube-scheduler
scheduler是k8s集群中负责调度的组件。它监听apiserver,查询未绑定Node资源的Pod,并跟据调度策略为其选择一个最合适的节点。
下面本节将从两个方面来介绍scheduler的实现:
- 初始化过程
- 单次调度过程
4.1 初始化过程
scheduler的初始化过程与其他组件非常类似。创建初始化配置,并将启动参数应用到该配置上,再基于此参数来运行scheudler,同样也会进行初始化参数的验证。
在运行前,scheduler会执行一些init方法注册调度策略(predicates过滤策略、priority优先级策略)register_predicates | register_priority、策略提供器配置(默认提供器和集群自动扩容提供器)defaults。位置位于algorithprovider/defaults。
注册时,注册的是策略构建工厂,并将其保存在全局变量中scheduler/algorithm_factory.go/。
注册的过滤算法有如下几种:
PodFitsPorts:被
PodFitsHostPorts取代
PodFitsHostPorts:检查是否有Host Ports冲突;
PodFitsResources:检查资源可用性(CPU、内存等是否充足),其也是默认的过滤策略;
HostName: 检查pod.Spec.NodeName是否与候选节点一致;
MatchNodeSelector:检查候选节点的pod.Spec.NodeSelector是否匹配;
NoVolumeZoneConflict:检查volume zone是否冲突;
MaxEBSVolumeCount:(废弃)检查AWS EBS Volume数量是否过多(默认不超过 39)
MaxGCEPDVolumeCount:(废弃)检查GCE PD Volume数量是否过多(默认不超过16)
MaxAzureDiskVolumeCount:(废弃)检查Azure Disk Volume数量是否过多(默认不超过16)
MatchInterPodAffinity:检查是否匹配Pod Affinity(亲和度)要求
NoDiskConflict:检查是否存在Volume 冲突;
GeneralPredicates:由多个过滤策略聚合,所有k8s组件都强制执行,包括PodFitsResources、PodFitsHost,PodFitsHostPorts和PodSelectorMatches;
PodToleratesNodeTaints:检查Pod是否容忍Node误点Node Taints;
CheckNodeMemoryPressure:检查Pod是否可以调度到MemoryPressure的节点上。
CheckNodeUnschedulable: 检查Pod是否可以调度到 带有Unschedulable的节点上;
CheckVolumeBinding: 检查是否能满足Pod的PVC上下界需求。
注册的优先级排序算法有以下几种:
SelectorSpreadPriority:优先减少同一
Service下的Pod在同一Node节点上的可能;
MostRequestedPriority:尽量调度到已经使用过的Node上,介绍节点使用;
RequestedToCapacityRatioPriority:跟据Node上的资源分配情况计算其分数;
ServiceSpreadingPriority:尽量将同一个service的Pod分布到不同节点上,被SelectorSpreadPriority替代
InterPodAffinityPriority:优先将Pod调度到相同的拓扑域上(如同一个节点、地域等);
LeastRequestedPriority:优先调度到请求资源少的节点上;
BalancedResourceAllocation:优先平衡各节点的资源使用;
NodePreferAvoidPodsPriority:跟据节点scheduler.alpha.kubernetes.io/preferAvoidPods注解来计算Node权重, 权重为 10000,避免其他优先级策略的影响;
NodeAffinityPriority:优先调度到匹配NodeAffinity的节点上;
TaintTolerationPriority:优先调度到匹配TaintToleration的节点上;
ImageLocalityPriority:尽量将使用大镜像的容器调度到已经下拉了该镜像的节点上。
注册的算法提供器,包含DefaultProvider和ClusterAutoscalerProvider,默认算法提供器为DefaultProvider:
- DefaultProvider 包含默认的过滤和优先级策略:
MaxGCEPDVolumeCount,MaxCSIVolumeCountPred,NoDiskConflict,CheckVolumeBinding,CheckNodeUnschedulable,NoVolumeZoneConflict,MaxEBSVolumeCount,MaxAzureDiskVolumeCount,MatchInterPodAffinity,GeneralPredicates,PodToleratesNodeTaintsSelectorSpreadPriority,InterPodAffinityPriority,LeastRequestedPriority,BalancedResourceAllocation,NodePreferAvoidPodsPriority,NodeAffinityPriority,TaintTolerationPriority,ImageLocalityPriority
- ClusterAutoscalerProvider 包含默认过滤和优先级策略:
MaxGCEPDVolumeCount,MaxCSIVolumeCountPred,NoDiskConflict,CheckVolumeBinding,CheckNodeUnschedulable,NoVolumeZoneConflict,MaxEBSVolumeCount,MaxAzureDiskVolumeCount,MatchInterPodAffinity,GeneralPredicates,PodToleratesNodeTaintsSelectorSpreadPriority,InterPodAffinityPriority,MostRequestedPriority,BalancedResourceAllocation,NodePreferAvoidPodsPriority,NodeAffinityPriority,TaintTolerationPriority,ImageLocalityPriority
初始化过程主要在创建Scheduler中,scheduler/scheduler.go/New,笔者第一遍阅读代码的时候发现一个很令人费解的事:Scheduler中存在另外一套插件式策略框架,该框架与之前的注册机制功能作用雷同。后来,从注释中得到了蛛丝马迹,Scheduler正在从第一种方式向第二种方式过度,下面我们将在scheduler的创建过程中介绍这种新的策略框架,插件式策略框架更佳抽象可拓展。
- 首先创建了
framework.Registry,其保存了所有可用的插件,以及相应插件的构建函数framework/plugins/default_registry.go/NewDefaultRegistry; - 同时构建了
DefaultConfigProducerRegistry,其保存了生成插件需要的配置生产者 - 根据参数生成不同的
Scheduler。- 若配置了
provider参数,则跟据策略提供者来创建; - 若用户自定义了
Policy,则通过策略配置来创建调度器,该模式下支持用户通过Extender来拓展实现第三方调度器;
- 若配置了
- 下面将介绍通过策略提供者的方式创建
Scheduler的过程 - 跟据
ProviderName从之前注册的策略提供者列表中捞出该种类型的策略提供者配置(配置了开启哪些策略),调用Configurator.CreateFromKeys来进行最核心的初始化流程;- 构建
过滤策略的配置,其包含两部分内容:一部分通过第一种注册构建工厂(这里称之为fitPredicates)的方式,另一种是通过插件式策略框架的方式framework plugins- 这两种方式对应的策略集存在交集。对于某种策略来说,若注册了插件配置构造器,则用插件的方式;
- 对于插件过滤策略,其会根据
predicates.Ordering()顺序进行排序;
- 构建
优先级策略的配置,其构建方式与上面构建过滤策略的配置的方式一致; - 利用上面的得到的配置参数,构建插件框架
framework(framework/v1alpha1/framework.go)- 筛选出所有需要的插件;
- 根据前面构建的
framework.Registry和framework来构建插件实体并进行保存 - 将创建的这些插件策略器按类型赋值给
framework的属性,如filterPlugins(对应过滤策略),scorePlugins(对应权重策略)。- 创建一个队列
SchedulingQueue,用来接收需要调度的Pod,其是一种优先队列PriorityQueue(后文将单独详细剖析其实现)。
- 创建一个队列
- 构建
- 创建完
Scheduler后,调用AddAllEventHandlers方法,该方法的作用是监听资源的变更,并回调Scheduler的方法,如监听pod资源变更回调Scheduler.addPodToSchedulingQueue方法; - 开启健康检查服务;
- 若配置了选主,则进行选主;
- 开启
Scheduler的后台运行任务,当有需要调度的Pod到来时,并最终调用scheduleOne。
4.2 单次调度过程
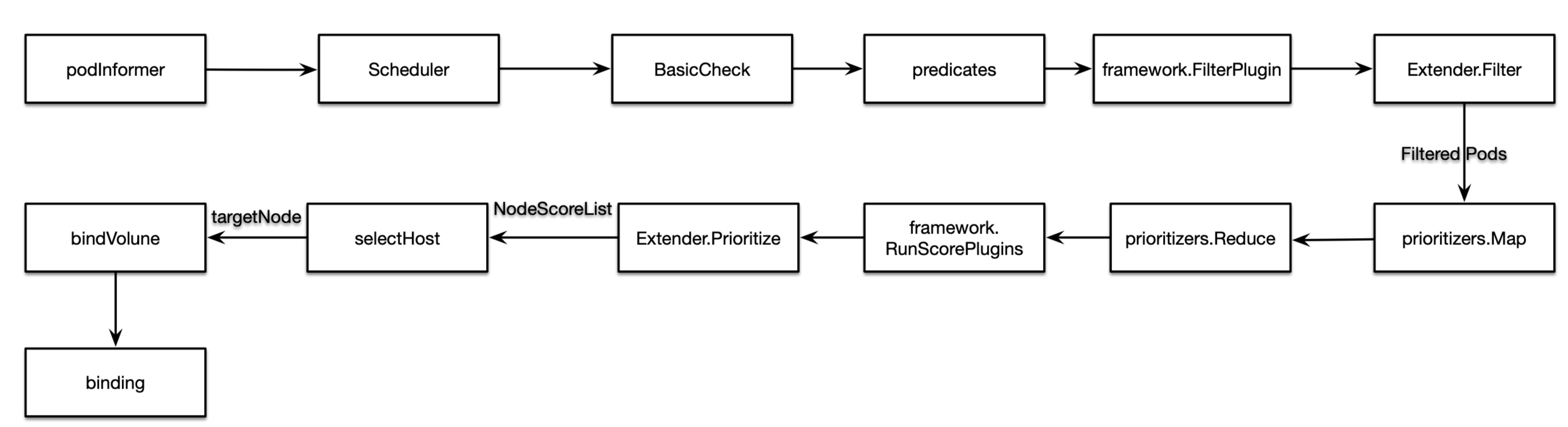
当ReplicaSetController创建Pod之后,Scheduler则会接收到Pod的更新消息,会调用addPodToSchedulingQueue方法,而方法则直接将Pod放入SchedulingQueue中。Scheduler.scheduleOne是调度的核心,其阻塞监听SchedulingQueue队列并进行调度,下面将详细介绍该调度过程:
- 阻塞调用
Scheduler.NextPod方法,该方法实际是阻塞等待SchedulingQueue; Scheduler接收到新建的Pod后执行Schedule执行调度;- 首先进行一些基础校验:检测
Pod设置PVC配置是否存在; - 为本此调度执行一次
Node节点缓存的快照; - 执行
PreFilter逻辑,若返回任何除成功以外的状态则终止流程(目前无实现); - 执行
findNodesThatFit逻辑,执行过滤策略,筛选出可备用Node节点列表;- 首先计算参与调度的
Node节点数量(Scheduler为了提交调度的性能,当节点数量众多时,则每次调度的时候不会选取所有Node节点)- 若节点数小于
100,或者配置的percentageOfNodesToScore大于100时,所有节点参与调度; - 否则只选出
percentageOfNodesToScore个Node节点参数调度;当然若按百分比选出的节点数小于100时,返回100
- 若节点数小于
- 以
16并发执行podFitsOnNode方法筛选可用的Node节点候选列表podFitsOnNode方法执行比较复杂,其涉及到抢占式调度的计算;- 首先通过
addNominatedPods方法查看当前Node节点上是否有比当前Pod权重大的nominatedPod(通过通过调度要运行在该节点上但未真正运行在该节点上) - 运行通过老的筛选策略
fitPredicates查看是否可以调度到该节点上; - 再运行
插件过滤策略检测是否可以在Node上执行; - 当任何一个运行结果显示不合适时则立即返回;
- 若匹配成功且
Node节点上无nominatedPod,则返回该节点,表示可以调度到该节点; - 若匹配成功但
Node上有nominatedPod时,则再次运行依次过滤匹配过程(twice),运行两次的原因是,(源码注释中写的很绕):- 当没有
nominatedPod时,运行第二遍很可能通不过(pod affnitity策略),而``; - 当将
nominatedPod视为运行状态时,anti-affinity策略很可能失败;而将nominatedPod视为非运行状态时,则pod affinity可能无法通过,因此不能假设nominatedPod是什么状态,所以运行第二次是有必要的- 当系统配置了第三方调度服务时,则会通过
Extender(目前有HttpExtender)将上一步运行的结果带去请求第三方服务进行进一步的匹配;
- 当系统配置了第三方调度服务时,则会通过
- 当没有
- 首先计算参与调度的
- 当调度结果只有一个时,则直接返回结果;
- 执行
prioritizeNodes- 当没有配置
权重策略时, 返回输入的节点; - 16并发计算每种
prioritizers策略对每个节点的权重;Map操作:计算每个节点的结果集;Reduce(如果有的话):聚合每个节点的结果集,并计算每个结果的最终结果(归一化)
- 调用调度框架计算每种权重插件的分数:
RunScorePlugins- 16并发运行权重插件,计算每种插件针对每个节点的分数;
- 16并发为每个节点的分数乘以每个插件的权重
- 汇总上面两个计算结果,总结成每个
Node的分值 result; - 最后一步,请求
Extender计算每个节点的分值并整合到result上。
- 当没有配置
- 根据结果,选中分值最大的
Node,当有多个分值一样大的节点时随机选择一个
- 首先进行一些基础校验:检测
- 在绑定
Node之前,先绑定vloume资源; - 设置
Pod节点的SuggestedHost,从SchedulingQueue中删除作为notimatedPod的本pod,将该pod添加到node信息里,将该node移到最前(LRU); - 与
apiserver进行绑定,将pod绑定到node上。
简单总结其流程如下:
PriorityQueue
Scheduler中PriorityQueue有着特别的设计,其实现SchedulingQueue接口(存储Pod并等待被调度)。
本小节将从初始化和单次添加pod两个方面来介绍它:
初始化
首先,先来了解其数据结构:
1 | type PriorityQueue struct { |
创建完这个PriorityQueue后开启后台任务run:
- flushBackoffQCompleted: 从
podBackoffQ中捞出超过backoff时间的pod重新放入activeQ中进行调度(每秒运行一次); - flushUnschedulableQLeftover:将呆在
unschedulableQ中时间超过durationStayUnschedulableQ(60s)时间的pod移到activeQ或者podBackoffQ中(每30秒运行一次)单次入队&弹出
PriorityQueue.Add方法用于入队:
1 | func (p *PriorityQueue) Add(pod *v1.Pod) error { |
直接添加到activeQ队列中,并且从unschedulableQ和podbackoff!中删除。
弹出方法Pop:
1 | func (p *PriorityQueue) Pop() (*framework.PodInfo, error) { |

