3. controller-manager
controller-manager是整个k8s的大脑,
其由kube-conrtoller-manager和cloud-controller-manager组成。其中clound-controller-manager用来配合云服务提供商的控制,因此本章将不对其做详细描述。controller-manager中包含众多控制器见附件^1,通过这些控制器来完成集群管理的作用。监控集群状态,并确保集群处于预期的状态。
本节,将从如下几个方面来讲解controller-manager的工作原理:
- 启动过程
- 单次部署的执行过程
- pod自动横向伸缩工作原理
3.1 启动过程
controller-manager启动入口cmd/kube-controller-manager/controller-manager.go,与apiserver一样其也是基于CLI框架Cobra来实现。
其初始化过程如下:
- 首先创建一个带有默认参数的
KubeControllerManagerOption,用于构建控制器管理器;- 其中带有各控制器创建的配置参数
- 通过
cobra将输入参数应用到KubeControllerManagerOption上,运行前,会先对参数进行校验; - 跟据
KubeControllerManagerOptions构建创建众多控制器的配置参数kubecontrollerconfig.Config- 跟据输入参数构建与
apiserver交互的client; - 创建用于选主的通信客户端
leaderElectionClient; - 创建一个事件记录器,用于记录事件并将事件以
v1.Event发送给apiserver; - 将
KubeControllerManagerOptions中的配置应用到kubecontrollerconfig.Config。
- 跟据输入参数构建与
- 开启运行
控制器管理器。- 为
controller-manager创建两个http服务,分别用来做健康检查、配置查询; - 若配置需要选主,则先选主(没有那么复杂, 只是先到先得的原则)。若选主成功则开始初始化其内部组件,众多控制器;
- 运行组件
- 创建控制器上下文
ControllerContext,实际是提前构建一些通用的组件- 分别创建两个
Informer工厂,shared-informers以及metadata-informers; - 等待
apiserver就绪,最多等待10s; - 查询
apiserver中所有可用的资源; - 创建云提供商工具
- 跟据控制器上下文来开启控制器
- 开启
ServiceAccount控制器; app/controllermanager.go.NewControllerInitializer方法中保存了所有控制器的初始化函数,遍历并执行所有控制器的初始化函数,开启这些控制器的执行。比如DeploymentController、ReplicaSetController等;
- 开始两个
Informer工厂,开始同步并监听资源更新。
- 分别创建两个
- 创建控制器上下文
- 为
到此就完成了controller-manager的初始化过程。
下面我们以DeploymentController来讲解其初始化详细过程,DeploymentController的初始化函数是startDeploymentController:
1 | dc, err := deployment.NewDeploymentController( |
可以看到,其关注监听Deployment、ReplicaSets和Pod资源。再继续查看DeploymentController的创建过程,其关注这三种资源,并且添加事件监听器,当Deployment资源更新时回调addDeplotment\updateDeployment\deleteDeployment方法,ReplicaSets和Pod的更新也会回调DeploymentController的相应方法。
1 | dc := &DeploymentController{ |
创建完成后,调用Run方法开始运行DeploymentController,当然运行前需要这三种资源都从apiserver同步到其本地,然后开启多个协程执行worker逻辑。worker从Controller自身的queue中阻塞式等待数据,然后执行syncDeploymet方法,这里则是其的核心处理逻辑。
3.2 pod单次部署执行过程
单次执行Deployment进行部署时,其经历主过程如下:DeploymenetController接收创建Deployment的请求,进行解析创建ReplicaSet资源,而后ReplicaSetController接收到创建ReplicaSet的请求则创建响应的Pod资源信息。
除了简单部署之外,各控制器组件同时需要保障部署运行实情与期望一致。以下就是部署过程的简要流程图:
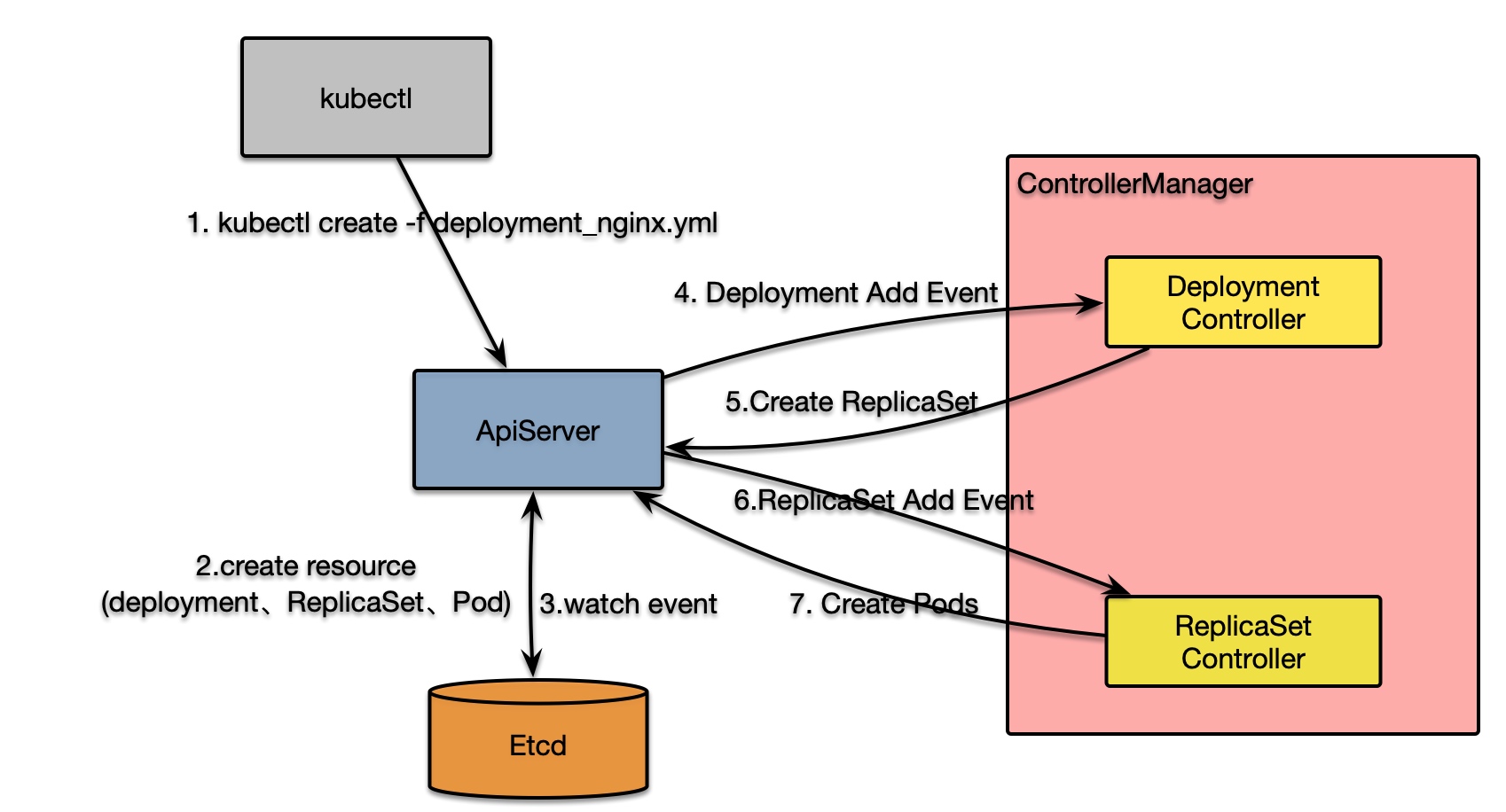
下面将详细介绍其执行流程:
kubectl执行create deployment.yml命令后,apiserver接收请求,并将其保存到etcd中;- 由于
controller-manager中的DeploymentController,所以变更会推送到DeploymentController的deploymentInformer中,而deploymentInformer则会回调DeploymentController.addDeployment方法; addDeployment方法并不会立即处理Deployment,而是将该Deployment生成的唯一key 入队列queue(该队列支持限流);DeploymentController.processBexrWorkItem会阻塞等待队列中的资源更新(系统可以启动多个工作协程同时监听该队列,以提升吞吐),最后会调用核心方法syncDeployment进行处理;DeploymentController.syncDeployment方法不仅处理初次部署的情况,同时也负责更新以及由其发起的部署集群发生变化的处理逻辑:- 通过
key获取发生变更的Deployment; - 获取该
Deployment创建的ReplicaSet,这里因为是新创建的Deployment所以查询不到ReplicaSet; - 获取该
Deployment间接创建的所有Pod - 若
Deployment的属性DeletionTimestamp不为空时表示该Deployment被删除,则只同步状态; - 检查
Deployment是否被暂停或者恢复,并设置相应的状态,若被暂停则进一步进行清理; - 若该
Deployment是进行回滚操作,则执行rollback回滚相应逻辑; - 检查
Deployment是否需要进行扩缩容(通过检查其对应的ReplicaSet所有的分片数与理想状态是否一致来判断) - 若是扩缩容事件,则执行同步方法
sync - 若不是,则是初次创建,部署时有两种策略:Recreate、RollingUpdate(针对升级的情况,默认是RollingUpdate),这里我们就以
RollingUpdate为例来查看其执行过程(DeploymentController.rolloutRolling):- 首先会获取所有新老
ReplicaSet。当不存在ReplicaSet时,则跟据Deployment属性创建一个ReplicaSet,并发送到apiserver(DeploymentController.getNewReplicaSet); - 更新
Deployment的状态
- 首先会获取所有新老
- 通过
ReplicaSetController监听ReplicaSet的更新,上面DeploymentController创建ReplicaSet后,ReplicaSetController会受到通知(与DeploymentController执行方式一样,也通过queue和多个worker来处理更新)并最终调用ReplicaSetController.syncReplicaSet方法:- 获取同一命名空间内的所有存活的
Pod; - 并通过
ReplicaSet的Selector筛选出由其创建的Pod; manageReplicas方法管理ReplicaSet,计算已经创建的Pod数和ReplicaSet的预期的Pod差值- 当
Pod数不足时,则依次跟据ReplicaSet的配置PodTemplateSepc创建Pod,同时设置上Pod的OwnerRefernce(用于gc); - 当
Pod数过多时,则并发删除多余的Pod。
- 当
- 更新
ReplicaSet的状态。
- 获取同一命名空间内的所有存活的
到此就完成了Pod的创建,但创建的Pod还不能工作,需要被调度到某个Node上才能运行。至于应该被调度到哪个节点上,这就涉及到调度器的实现逻辑,将在下节scheduler中介绍。
3.3 pod自动横向伸缩
k8s中负责pod自动横向伸缩的控制器叫HorizontalController。首先看其控制器初始化:
1 | func startHPAController(ctx ControllerContext) (http.Handler, bool, error) { |
HorizontalController的初始化过程流程主要做了以下几件事:
- 创建
Metrics查询客户端; - 创建分片计算器;
- 创建
hpa资源informer,监听该资源变更并回调相应的函数enqueueHPA、updateHPA、deleteHPA
下面将来详细介绍其运行原理:
通过kubectl执行autoscale命令kubectl autoscale deployment nginx-deployment --cpu-percent=30 --min=7 --max=8后,HorizontalController会接收到HorizontalPodAutoscaler新增消息,最终会执行HorizontalController.reconcileAutoscaler方法。该方法是控制器的核心逻辑,其执行过程如下:
- 通过
hpa的属性获取对应资源(可以是Deployment也可以是其他)的Scale中的分片数信息; - 进行逻辑判断:
- 若当前分片数为0但最小分片数不为0,则不进行自动扩容;
- 若当前分片数大于
hpa定义的最大分片数则将目标分片数(desiredReplicas)设置成最大分片数; - 若当前分片数小于
hpa定义的最小分片数则将目标分片数设置成该最小分片数; - 都不满足的话则执行第三步跟据
Metrics信息计算需要部署的分片数
- 执行
HorizontalController.computeReplicasForMetrics方法计算目标分片数:- 定义
hpa时可以定义多个指标维度的扩缩容策略,比如cpu等。因此这里会按每个指标信息依次计算目标分片数,最后取最大值作为最终的目标值; - 对于指标(
MetricSpec),k8s对齐进行了分类,主要分为四类,没类的计算方式也不同:- Object: 描述
k8s对象,如hits-per-second; - Pods: 描述目标中每个
Pod信息,如transactions-processed-per-second,而这些值在比较前会进行求平均; - Resource:是
k8s中一个知名度量信息,在request和limit中进行定义的资源; - External:拓展指标信息,来自于
k8s集群之外的信息。- 下面以
Resource为例,来讲解其计算过程(HorizontalController.computeStatusForResourceMetric):
- 下面以
- 最终调用的是
ReplicaCalculator分片计算器的GetRawResourceReplicas方法; - 首先,通过
metricsClient查询每个Pod的Metrics信息; - 进行以下条件判断和计算目标分片数
- 首先计算当前测量的
metric的平均值和目标值的比例(usageRatio); - 若没有未就绪的
pod且当前指标大于目标值时:- 当差值在10%(默认
可容忍值)之内,则直接返回原值; - 若大于10%时,则返回分片数:
usageRatio乘以当前Pod数;
- 当差值在10%(默认
- 如有
Pod未收集到指标信息- 当
usageRatio小于0,将未收集到的指标设置零时为目标值; - 若
usageRatio大于0,将未收集的指标设置零时为0;- 当
usageRatio大于0,将所有未就绪的Pod指标设置为0 - 对修改过的数据重新计算
usageRatio; - 当新的
usageRatio<1.1(0.1是容忍度)或者oldUageRatio<1&&newUsageRatio>1或者oldUageRatio>1&&newUsageRatio<1时,直接返回原值; - 否则返回
newUsageRatio乘以所有pod数量(也及以newUsageRatio比例来扩容)
- 当
- 当
- 首先计算当前测量的
- 并不是计算出来就用这个值,还需要对伸缩速率做一次调整(
normalizeDesiredReplicas):- 根据历史值来调整该值(
stabilizeRecommendation):HPA中保存每次计算结果和时间戳,timestampedRecommendation;HPA启动时会设置一个窗口期downscaleStabilisationWindow(默认5min)- 找到窗口期之内历史计算结果,若历史推荐分片数比当前推荐的大,则覆盖当前的
- 速率限制(
convertDesiredReplicasWithRules)- 防止扩容过快,限制最大不能超过当前实例数的两倍;
- 获取目标分片数时,若与原值不相等则通过
Scales接口将分片数修改成目标值(实际,Scales只是一个包装,其实质是更新Deployment的Replica只) - 当
DeploymentController接收到更新后,就会引发其扩缩容操作,上一小节中已经介绍。
到此,HPA的单次操作执行流程就介绍完了,下面以一张图来简要描述该过程: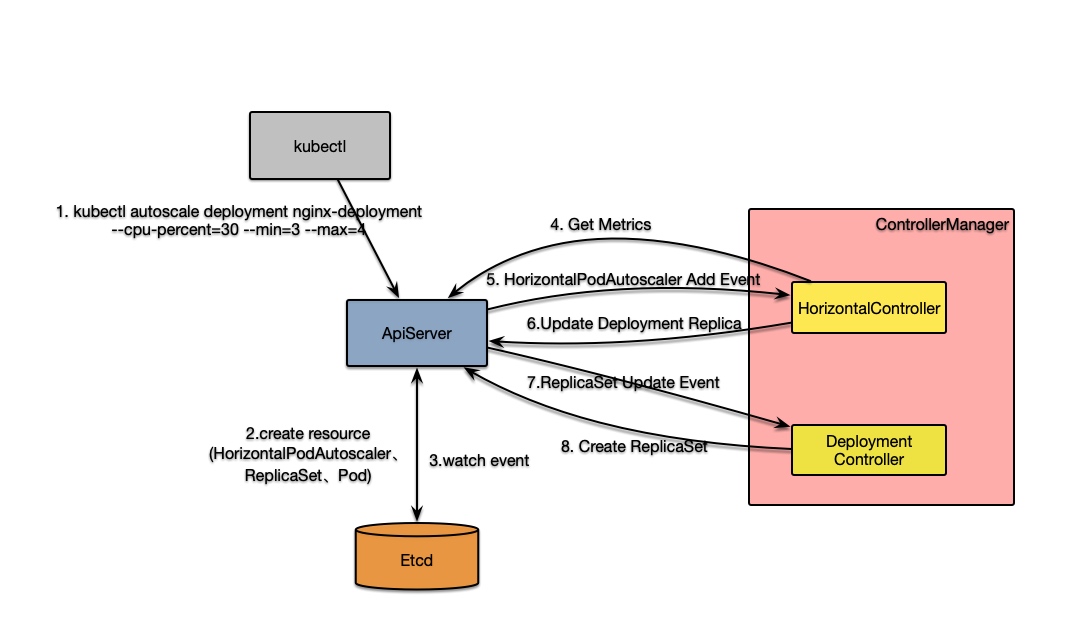
- 获取目标分片数时,若与原值不相等则通过
- 防止扩容过快,限制最大不能超过当前实例数的两倍;
- 根据历史值来调整该值(
- Object: 描述
- 定义
附件
1. 控制器列表
1 | controllers := map[string]InitFunc{} |

