1. RocketMQ 整体架构
[TOC]
整体架构
RocketMQ主要由四部分组成,NameServer、Broker、Producer、Consumer。其中NameServer、Broker是独立部署集群,而Producer、Consumer一般是以SDK的形式提供给业务方,嵌在业务集群内。另外还有一个FilterSrv,可选择性使用,用于消费者自定义消息过滤。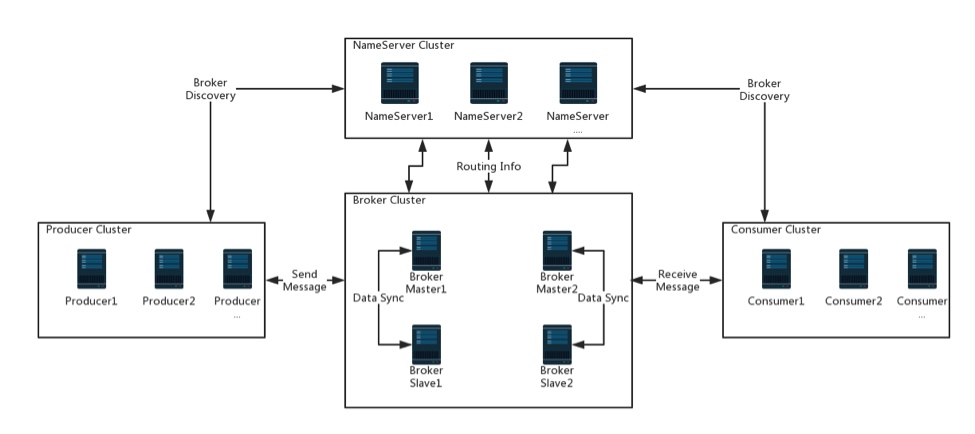
NameServer
类似于服务治理框架里的注册中心。管理Broker集群的注册信息并提供心跳来检测他们是否可用,持有关于broker集群和队列的全部路由信息;
Broker
负责消息的存储传递,客户端查询并保证高可用。此外,代理提供了灾难恢复、丰富的度量统计和警报机制。主要功能如下;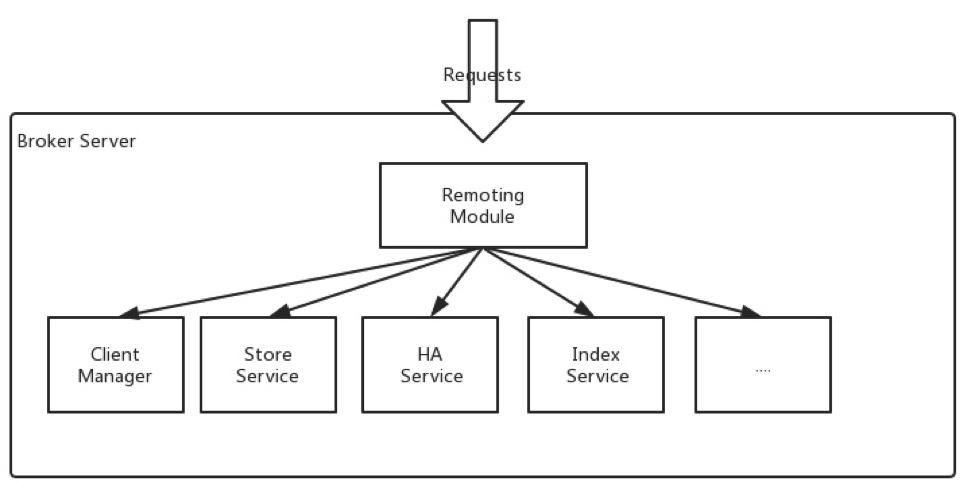
Remoting Module:服务入口,接收来自客户端的请求并转发;Client Manager:客户端管理,管理客户端(生产者/消费者)还有维护消费者主题订阅;Store Service:信息存储和查询的api服务;HA Service: 提供主从broker的数据同步;Index Service:为消息建立索引提供消息快速查询。