0. ETCD简介
本文将从以下几个方面来分析 ETCD (v3.3.12)。
- 整体架构
- 启动过程
- 数据存储
- 通信方式
- TTL实现原理
- Lease实现原理
- 单次事务过程
- 线性一致性读过程
- Watch机制
在介绍上面所有过程之前,我们先来介绍下 ETCD的整体架构以及相关名词术语。
1 | - Node:一个Raft状态机节点; |
peer间通信消息类型:
1 | - MsgHup // 不用于节点间通信,仅用于发送给本节点让本节点进行选举 |
Etcd整体架构图如下: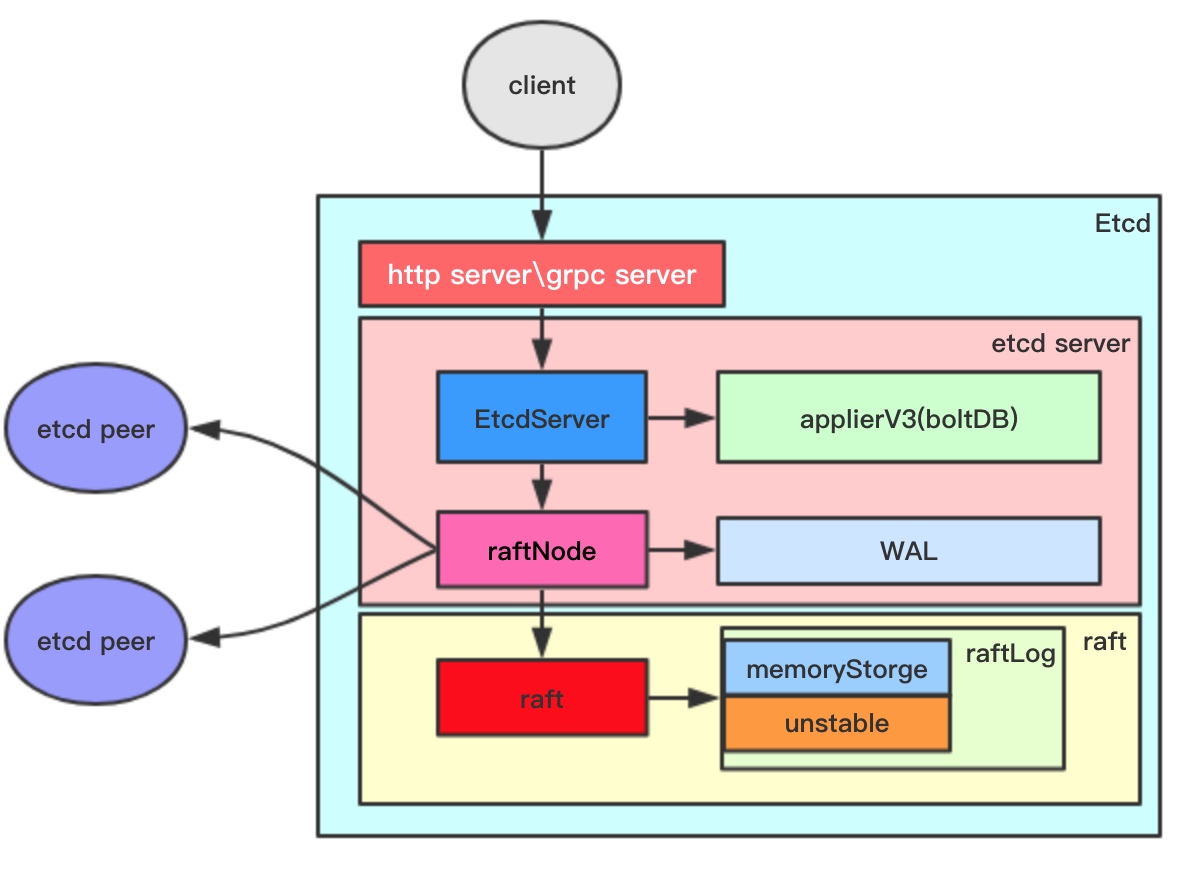
下面将简单介绍下:
etcd面向client和peer节点开放http服务以及grpc服务,对于像watch机制就是基于grpc的stream通信模式实现的;EtcdServer是etcd上层结构体,其负责对外提供服务,且负责应用层的实现,比如操作应用层存储器,管理leassor、watch;raftNode负责上层与raft层的衔接。其负责将应用的需求传递到raft中进行处理(通过Step函数)、在消息发送到其他节点前将消息保存到WAL中、调用传输器发送消息;raft是raft协议的承载者;raftLog用于存储状态机信息:memoryStorge保存稳定的记录,unstable保存不稳定的记录。
1. Etcd初始化流程解析
Etcd的启动类为 父目录的main.go文件。其启动过程调用如下:
1 | main.go |
startEtcd中执行etcd启动的主要过程:
1 | embed.startEtcd(inCfg *Config) |
通过 cfg.PeerURLsMapAndToken(“etcd”) 逻辑,了解到etcd有三种方式来获取集群中其他节点信息:
1 | switch { |
准备好创建etcd节点后开始初始化节点信息:
1 | etcdserver/NewServer(srvcfg) |
初始化快照管理器和数据库后端后,就会根据一系列条件来决定怎样启动节点:
1 | switch { |
创建完raft.Node并绑定相应raft后,继续初始化:
1 | |- stats.NewServerStats // 初始化统计计数 |
下面来看raftNode的详细创建过程:
1 | newRaftNode( |
可以看出raftNode和raft.node之间的关系。通过raftNode可以直接访问raft.node的所有公有方法。
回到 startNode 方法,我们以新集群且没有WAL文件的场景来了解下startNode的处理过程:
1 | etcdserver/raft.go/startNode |
下面我们来详细了解下newRaft的内容:
1 | newRaft(c *Config) *raft |
接下来,再来看 becomeFollower 方法,其设置了 step 方法和 tick 方法、设置了 raft所在任期以及raft的角色状态。我们都知道raft协议中共有三个角色Follower、Candidates、Leader。etcd中通过不同角色设置不同的step来区分开每个角色的处理逻辑,设置不同tick方法来设置超时任务(对于Follower角色,其超时后会发起新一轮选举,而对于Leader角色,则广播一次心跳消息… )
1 | func (r *raft) becomeFollower(term uint64, lead uint64) { |
到此,就完成了 EtcdServer的创建。
接下来,再来看EtcdServer的开始方法Start:
1 | EtcdServer/Start |
EtcdServer.start()方法,首先进行一系列通道的初始化,然后异步执行EtcdServer.run()方法:
1 | EtcdServer.run |
展开 raftNode.start(rh)的逻辑如下:
1 | select { |
完成etcdServer的启动后,开始http/grpc服务对外提供服务(peer间的服务以及对client开放的服务)。
我们以servePeers()来讲解启动服务过程。
1 | servePeers() |
当新连接到达时,处理流程如下:
1 | cMux.Server() |
到此整个初始化过程就完成了。其后开始进行选举,那么选举是哪里出发的呢?
回到创建raftNode的地方 r.ticker = time.NewTicker(r.heartbeat) 开启了ticker。当时间到达时,tickder.C中得到通知。而其正在被 raftNode的start方法中的循环监听着。进一步就触发了raftNoe.tick()方法。
1 | raftNoe.tick() |
当其他接收到该节点的投票请求时:
1 | peer.go/startPeer(180L) |
当节点收到 其他的投票反馈消息时,最终会调用 raft.go/stepCandidate方法。
1 | // poll方法传进去本消息的投票,返回已经有多少赞成票 |
通过上面的逻辑,可以看出,当投票数达到quorum数时,转变角色为主节点。同时向所有其他节点广播本节点状态以及记录信息(MsgApp),其他节点接收到此消息后,自动转变为 follower角色,整个集群初始化完成。
对于etcd的选举,还需要说明的是,etcd为了某些网络分区的问题了设置PreVote流程(只需要启动节点的时候 设置 pre-vote 参数)。即在进行真正的选举之前 先进行PreVote得到大多数节点同意选举之后才进行真正的选举。可以解决如下问题:
- 对于网络分区的节点,在重新加入集群的时候不会中断集群;(因为获取不了大部分节点的许可,索引其
Term无法增大,所以赢不了选举主节点)。
到此,etcd的启动到建立集群、完成选举的整个过程就介绍完了。
附加图:
下图为 EtcdServer、raftNode、raft.node、raft间的联系。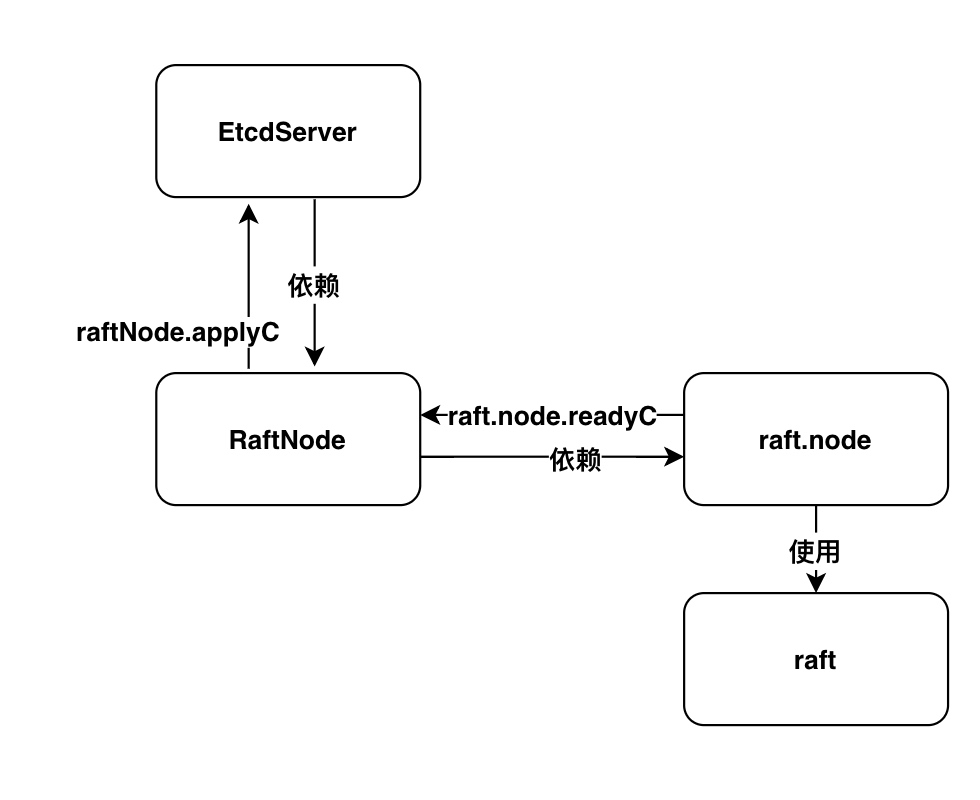
最后补充说明下etcd的proxy模式:etcd可以通过命令./etcd –proxy on –listen-client-urls的形式启动代理模式。代理模式下,它的作用是一个反向代理,接收客户端请求,然后转发到etcd集群。
代理模式有2种运行形式:readwrite和readonly,默认情况下为readwrite,即会将读写请求都进行转发,而readonly形式下,则只转发读请求,写请求将报5xx错误,
IDEA中启动ETCD方式:
1 | debug方式运行三个终端程序 `etcd/main.go` 并设置如下参数: |
3. 数据存储
Etcd的存储部分,可以分两部分来讲解。一部分是其应用层的数据存储方式,另一部分是raft相关数据的存储。Etcd应用层的数据存储从v3版本开始就延用boltDB,其也是CoreOS的产品boltDB。PS:本文主要聚焦于v3版本,对于v2版本不作解读。
下面将分别介绍这两部分内容:
3.1 raft数据存储
首先我们来介绍下raft相关的数据存储:raft中有两个比较重要的组件:
raftLog:用来保存状态机相关信息的,包括当前任期、索引号、不稳定记录项等;WAL:预写日志器,用于以顺序形式写入操作记录,以便故障时数据恢复;Snapshot:数据快照,一般用于启动时快速恢复数据。
首先来看raftLog:
1 | type raftLog struct { |
下图描述了数据从客户端请求到落地各个阶段与以前存储结构的关系: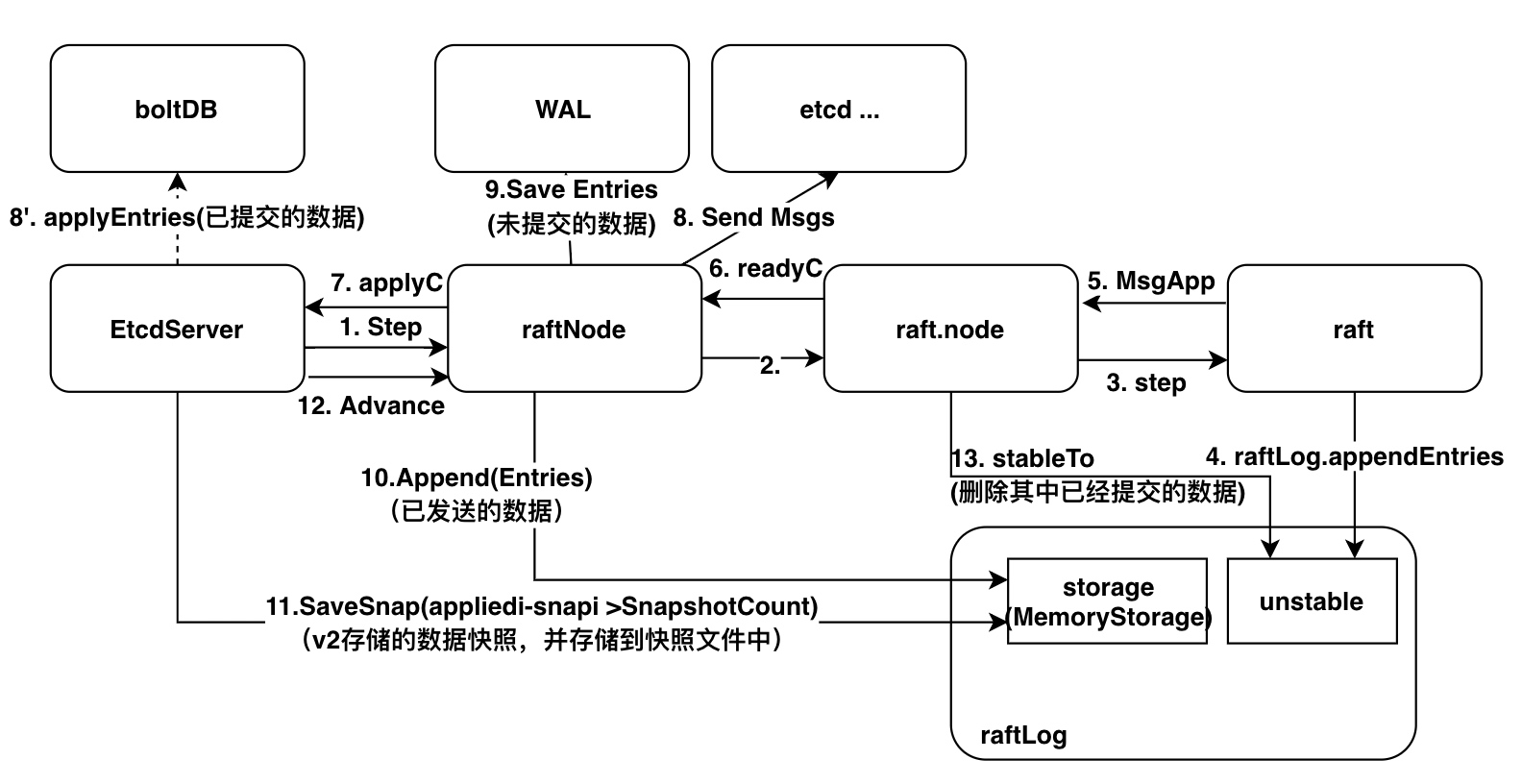
其中,8’、9、11 是涉及 I/O 的操作,其他均为内存操作。
对WAL的操作在每次写事务操作中都会存在,因此其是制约etcd写性能的一个重要因素。接下来,将重点介绍WAL的工作原理。
1 | type WAL struct { |
首先,来看其创建过程:
1 | wal.Create |
创建WAL时,会初始化编码器以及FilePipeline。下面再以其Save方法来介绍保存记录的过程:
1 | WAL.Save |
随着记录的增加,wal文件会越来越多,入股不做处理的话会导致磁盘被占满。那么etcd是怎么做的呢?
其实是由两步构成的:
- 当
etcd每次进行执行快照的实时,会进行wal.ReleaseLockTo(snap.Metadata.Index)释放文件锁的操作。(释放快照对应索引号之前的所有WAL文件句柄) - 之前在
EtcdServer启动章节介绍过,其启动后会启动一个定时任务purgeFile。其会针对snap.db、snap、wal文件做30秒一次的fileutil.PurgeFile任务:- 任务带有参数
MaxWalFiles,获取指定wal.dir下所有文件,然后按文件名排序,从小到大进行遍历:尝试锁文件。如果成功,则进行删除,否则的话说明依然被etcd锁占用。
- 任务带有参数
3.2 应用数据存储
在解析etcd应用层数据存储结构前,先来介绍下etcd的数据存储形式。etcd对数据的存储并不是直接存储key-value对,而是引入了一种带版本号revision的存储方式:以数据的revison为key,键值对为值。revision由两部分组成:main-revision.sub-revision。main-revision为事务ID,sub-revision为事务中一次操作ID。
举例来说:
系统刚启动后,在一个事务中执行put ty dj \n put dj ty两个操作,实际存储的是
- {1,0} key=ty val=dj
- {1,1} key=dj val=ty
紧接着执行第二次操作:put ty dj90 \n put dj ty92,那么存储中会追加如下信息:
- {2,0} key=ty val=dj90
- {2,1} key=dj val=ty92
而为了支持这种存储形式快速查询,etcd建立了treeIndex结构,用于建立key与revision间的关系。随之,通过key查询val的过程如下:
treeIndex是一个b-ree,其存储这keyIndex信息。KeyIndex的结构如下:
1 | key []byte |
keyIndex中,需要特别说明的是generation数据内部,保存的revs,如果最后一项为tombstone,则表示在这个代中被删除了。被tombstone的generation是可以被删除的。针对此,keyIndex有个专门的函数compact,compact(n)可以将主版本小于n的数据。
将完了其存储结构和存储格式,下面将从启动和执行一次操作两个流程来讲解其的工作原理。对boltDB不了解的读者建议先去了解下 boltDB、boltDB学习。
3.2.1 启动过程
etcd应用层存储创建过程如下:
首先创建backend,其是对boltDB的封装,加入一些批量提交逻辑。
1 | bepath := cfg.backendPath() |
有了backend后,会再基于此作一层封装:mvcc.New(srv.getLogger(), srv.be, srv.lessor, &srv.consistIndex),其内部包含watcher处理机制:
1 | mvcc.New |
这里我们比较关注的是NewStore逻辑:
1 | mvcc.NewStore |
由此就完成了treeIndex和boltDB的初始化。
最后,etcd又对mvcc.watchableStore进行了一次封装srv.newApplierV3Backend(),其用于衔接存储和raft消息请求。
3.2.2 请求应用到存储
put ty dj请求通过raft协议提交决策后,最终会调用到applierV3backend.put方法进行应用:
1 | applierV3backend.put |
到此就完成了存储模块的讲解。
2. 网络通信
在上一节,我们介绍了etcd集群的启动过程。在其中也简单介绍了会初始化与其他成员节点通信的连接,以及启动为其他成员节点提供服务的GRPC服务和Http服务以及启动服务客户端的服务。本章我们将详细介绍通信相关的实现。
2.1 成员节点间通信(peer)
前一章节介绍了peer服务端启动过程。下面,我们来讲解下调用端是如何初始化以及如何调用的。
与成员节点间通信传输的初始化之前介绍过,是调用Transport.AddPeer方法。
前面我们介绍了Transport的作用:向成员节点发送raft消息,并从成员节点获取raft消息。下面将详细描述其作用。
首先来看其初始化和启动过程:
1 | tr := &rafthttp.Transport{ |
接下来,继续了解AddPeer实现:
1 | Transport/AddPeer |
从上面的流程可以看出 peer使用stream模式通信方式。读写分别用不同的协程去监听处理。其中streamWriter负责消息发送,streamReader负责消息接收。见下面详情:
1 | w := &streamWriter{ |
streamWriter里比较关键的一点是,这里的conn从哪来?往cw.connc传递conn的只有peer.attachOutgoingConn方法。
而在上面初始化并启动peer的时候是没有发现调用这个方法的 ???哪是哪里进行执行的呢?通过 追踪peer.attachOutgoingConn的调用方,最终发现,其在rafthhtp/http.go/ServeHTTP() L483处调用。而这个方法会在客户端建立连接进行http服务调用的时候执行。所以,在这里调用 peer.attachOutgoingConn 的作用是复用连接。当我们分析完读处理过程后,再来整体看 etcd节点是怎么建立通信链路的。
StreamReader的处理比StreamWriter的处理要简单一些。初始化完其属性后,调用start方法启动监听读请求过程。
1 | StreamReader/start |
这样每个peer之间的链路就建立了。回过头来,可以看出每对peer之间至少会有两条connection。且他们之间交互交错使用。
单peer往对方发送的消息,是通过 对方跟自己建立的连接 来发送的。
最后,我们通过单次请求响应过程,来介绍节点间的通信过程。
当要想集群其他成员节点发送消息时,最终会调用peer.send方法:
1 | peer.send |
目标节点的 StreamReader(p.msgAppReader)接收到消息后,通过解析后传递到 EtcdServer(Process),即完成单次通信;对于请求的响应,则通过对方的peer来发送给本节点,本节点的StreamReader来接受响应消息。
2.2 客户端通信
对于客户端通信,因为是GRPC或者HTTP简单的请求响应方式,因此这里就不再介绍了。
4. 事务请求
[TOC]
本节我们将讲述 etcd集群的事务请求处理过程。首先我们将以put操作为例来讲解一般性事务请求过程。其次,我们将介绍 etcd特有的线性一致性读请求过程。
put 请求
通过 etcdctl put ty dj 命令,向本地监听2380端口的节点发送 写请求。
该请求为GRPC请求,会中转到quotaKVServer进行处理。
Leader接收请求,并广播消息
1 | quotaKVServer.Put |
接下来就进入了主要的处理流程:
1 | node.Propose |
可以看出 将请求两层封装之后传递给通道n.propc。
在node的循环中,其会监听proc通道,当有消息到来时:
1 | node.start | 360+L |
当本节点将需要发送给每个成员节点的消息都放到r.msgs后,node.run会进入下一轮循环。此时:
1 | node.run |
发送到n.readyc通道中的消息,会被raftNode捕获:
1 | for { |
以上是Leader角色接收到Put请求,然后自身进行处理,然后向 Follower发送MsgApp消息。
Follower接收到Leader的广播,进行处理回复
当Follower收到消息后,会执行EtcdServer.Process方法:
1 | EtcdServer.Process |
发送的消息最终被 raftNode接收:
1 | for { |
再看EtcdServer接收到apply消息后的处理:
再来看 EtcdServer
1 | EtcdServer/1020L+- |
总结起来,Follower节点接收到Leader节点的MsgApp应用到其节点中,然后向反馈Leader MsgAppResp消息,并带上自己的最大记录号。
Leader收到Follower的回复进行处理
Leader收到MsgAppResp消息后,经过层层传递到stepLeader方法中:
1 | |- pr := r.getProgress(m.From) // 获取该节点的进度 |
我们先来看判断是否可以提交的逻辑:
1 | raft.maybeCommit |
r.bcastAppend()的处理过程之前以及介绍过,其会构造一遍Ready数据结构,带上CommitedEntries提交的数据、其他节点未同步的Entries,传递给raftNode。raftNode接收到此消息后,会执行与上面分析的Follower的逻辑类似。
线性一致性读
线性一致性读和一般的读不通的时候,会在进行真正的读请求之前,先与其他节点进行一个check,查看当前集群主是否发生了变化。通过etcdctl get ty命令,向监听本地2380端口的节点发送GRPC请求,会被中转到quotaKVServer上。get请求在etcdctl中会被转换成Range请求。quotaKVServer最终会调用EtcdServer.Range方法。
Leader节点收到请求后,广播心跳消息
1 | quotaKVServer |
线性一致性读的主要逻辑体现在 s.linearizableReadNotify中。
1 | s.linearizableReadNotify // 线性读通知 |
EtcdServer在启动的时候会启动linearizableReadLoop线性一致性读循环。
1 | linearizableReadLoop |
1 | node.ReadIndex |
Follower接收到Leader的心跳请求,并返回
Follower接收到Leader的心跳请求,最终会调用:
1 | r.raftLog.commitTo(m.Commit) |
Leader接收Follower回复,通知客户端请求继续
Leader节点接收到Follower的回复后,最终会调用如下逻辑:
1 | pr.RecentActive = true |
raftNode结构体接收到Ready消息时,会检查是否有ReadStates,然后对其进行处理:
1 | if len(rd.ReadStates) != 0 { |
再回到linearizableReadLoop中:
1 | select { |
到此就完成线性一致性读的全过程。
5. TTL & Lease 实现
etcd中用来实现TTL的机制叫Lease,Lease可以用来绑定多个key。Lease的主要用法如下:
1 | 1. etcdctl lease grant 1900 // 申请一个租约,返回租约ID |
下面将解析其工作原理,首先将介绍其初始化过程,然后介绍创建、以及绑定key以及过期的操作。
5.1 初始化
Lessor是在创建EtcdServer是进行初始化的:lease.NewLessor(...)
1 | minTTL := time.Duration((3*cfg.ElectionTicks)/2) * heartbeat // 首先计算最小TTL单元,为选举跳数的1.5倍*心跳间隔时间 |
完成了Lessor的初始化后,随着进入kvstore.restore的初始化,会伴随着恢复key与lease的映射关系。
1 | 当从 bucket`key`中获取所有key-val后,执行`restoreChunk`方法 |
5.2 Lease创建
创建Lease,最终会调用EtcdServer.LeaseGrant方法。
1 | EtcdServer.LeaseGrant |
5.3 Lease绑定key
在put操作时通过添加参数--lease=326969472b0c5d08即将key绑定到lease上。直接定位storeTxnWrite.put方法:
1 | oldLease = tw.s.le.GetLease(lease.LeaseItem{Key: string(key)}) // 获取key之前绑定的`lease` |
5.4 Lease过期
上文中介绍过在初始化Lease后,会启动lessor.runLoop任务:
1 | for { |
6. Watch机制
watch用于监听指定key或指定key前缀的键值对的变动。其 api 如下:
1 | etcdctl watch --prefix[=false] // 带前缀 |
下面将详细解析其工作原理。首先将介绍其初始化过程,其次介绍创建watch过程以及相关键值对修改时的操作。
6.1 初始化过程
在初始化存储的时候,提到了newWatchableStore方法,其对boltDB进行了一次封装。
1 | s := &watchableStore{ |
首先来看下WatcherGroup的数据结构:
1 | type watcherGroup struct { |
总结整体流程如下:
- 首先从未同步watcherGroup中获取最多
maxWatchersPerSync个watcher对应的关注最小的Revision,并删除已经被压缩的watcher; - 使用上面得到的最小
Revision去获取所有key-val对; - 对所有
key-val对,去寻找关注其变化的watcher最终生成WactherBatch - 发送给客户端,然后将watcher从
unsync WatcherGroup中移动到sync WatcherGroup中。对于未发送完成的消息添加到victims中,在syncVictimsLoop中重试。
接下来即系了解syncVictimsLoop的实现逻辑:
1 | for { // 循环执行moveVictims方法 |
6.2 创建watch
当通过客户端执行如下命令etcdctl watch /ty/dj --prefix命令时,客户端与服务端建立grpc双工通道进行交互,其最终会调用watchServer.Watch方法,在其中建立双工通道交互方式。
1 | sws := serverWatchStream{ |
首先来看sws.recvLoop处理过程,通过grpcstream通道获取请求,然后调用watchStream.Watch方法创建watch,并注册到相应的WatcherGroup上。
1 | for ;; |
再来看发送流程:
通过watcher.send发送变更消息的时候,实际上是传递到watcher的ch通道上,而这个通道则是serverWatchStream的发送通道:
1 | select { |
6.3 键值对更改
建设有两个客户端A,B
A客户端先执行了操作etcdctl watch /ty/dj;B客户端随后执行了操作etcdctl put /ty/dj hello。那么在B执行该操作时watcher机制是如何work的?
对于put操作,会执行storeTxnWrite.put方法,会将更新的数据添加到 tw.changes中,最后会执行watchableStoreTxnWrite.End方法:
1 | changes := tw.Changes() |
总结过程如下:在进行put操作时会将变更添加到changes中。当put操作结束时,执行watchableStoreTxnWrite.End方法,转换成newWatcherBatch事件,然后调用watchableStore.notify方法进行发送更新。

