Zebra
[TOC]
Zebra是什么?能干甚么?
Zebra是一个在JDBC协议上开发的数据库连接池中间件,它不是真连接池(与DB直接交互的连接池),而是对连接池做了一层包装。
功能:
- 支持适配目前主流的数据库连接池(如上图)
- 读写分离、分库分表
- 支持配置动态修改生效(连接池的配置、用户密码、数据库节点访问路由负载均衡配置)
- CAT全方位监控(SQL执行情况、数据库连接数、端到端监控)
- 支持压测(改写表名)、SQL限流、黑白名单、SQL改写、SQL审计(日志审计,SQL安全监控)…
同类产品有哪些,以及比较?
| 类别 | 案例 | 优点 | 缺点 |
|---|---|---|---|
| 基于代理 | mycat、cobor、atlas、jed | 多语言支持、节省数据库连接 | 风险大(链路长)、实现难度大、共享连接时有风险 |
| 基于客户端(jdbc层) | tddl | 直连数据库(风险较小)、更灵活 | 对于每种语言都需要重写sdk、富客户端的常见缺点 |
基于代理: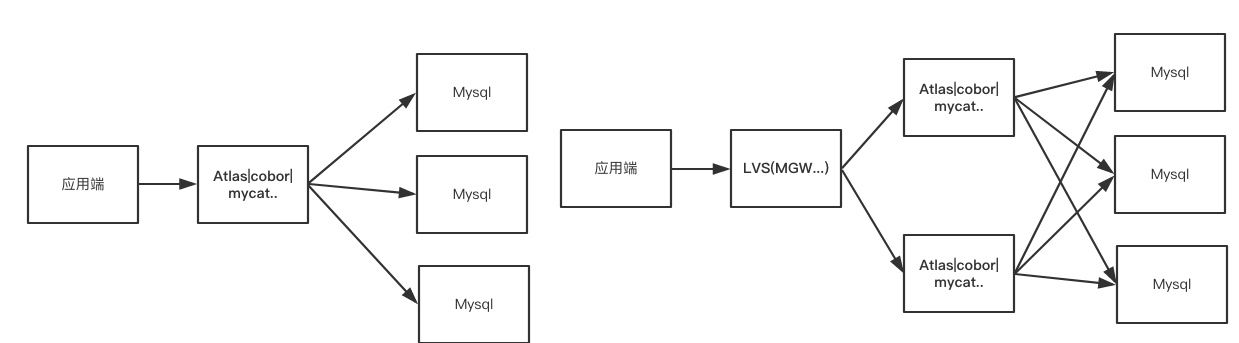
基于客户端: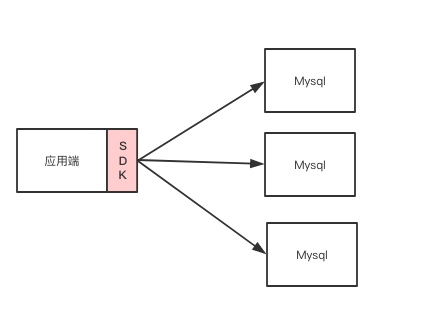
公司目前:北京侧
Altas居多,也有Atlas与zebra搭配使用(使用其压测处理、SQL监控特性),上海侧统一使用zebra。趋势是转向Zebra。Atlas与Zebra的对比。zebra秒杀Atlas?
数据库中间件比较
为什么美团一开始没有选择基于sdk的方式,而是基于代理的方式来做的?
架构

- Zebra客户端做读写分离、分库分表、打点、监控
- RDS、DBA管理平台维护配置信息
- Lion监听配置更新,通知客户端生效变更
- MHA保障主库的高可用性
- zebra-monitor(自研)保障丛库的高可用性
MHA(Master High Availability)是作为MySQL高可用环境下,操作故障切换、主从提升的一套解决方案。MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案。能做到30内完成故障切换。 官网。
PS: Atlas维护主的高可用性也是MHA,且和Zebra是同一个MHA。
高可用
主库的高可用
利用MHA进行master节点的可用性监控,在发生故障,master节点不可用时,MHA进行mysql层的主从切换,切换成功后通知zebra新master节点的IP,由zebra客户端负责应用访问层的切换。官方文档
切换流程如下:

- MHA对MySQL集群进行监控管理
- 当主库发生故障时,MHA通知zebra对主库的写进行关闭,并进行MySQL集群的主从切换(切换期间应用无法写数据)
- zebra禁止掉对故障集群的写操作
- MHA切换成功,通知zebra新的写数据IP
- zebra用新的写IP替换老IP,开放应用访问。
丛库的高可用
由zebra-monitor的监控服务负责,实时监控线上MySQL从库的健康状况,如果出现从库“故障”,将会通知zebra将读流量转移到其他可读节点,实现从库的“故障”转移。
丛库状态判断: zebra-monitor监控首先使用select 1 测试是否可以连通数据库,连接没有问题则使用 show slave status 获取到second_behind_master字段来得到该从库上的延迟,从而做出判断:
markdown(故障)
- 30s内从库连续ping不通; (从库宕机)
- 30s内 second_behind_master取到的延迟为null。 (主从同步中断)
- 延迟超过阈值。(可根据每个库的敏感程度进行个性化配置,需要进行另外配置)
故障处理:从库markdown,zebra客户端会收到通知动态刷新连接池配置,重建本地数据源配置,流量不会再走到故障丛库,老的数据源会在全部sql执行完成后被close。
markup(恢复)
- 30s内能够连续ping通并且主从延迟为0.
故障恢复:丛库恢复时,会通知客户端进行动态刷新数据源。
Zebra-client
##总览
推荐使用包搭配
zebra-api、zebra-ds-monitor、mtrace-zebra
zebra-api
ShardDataSource + m x GroupDataSource(Master + n x Slave)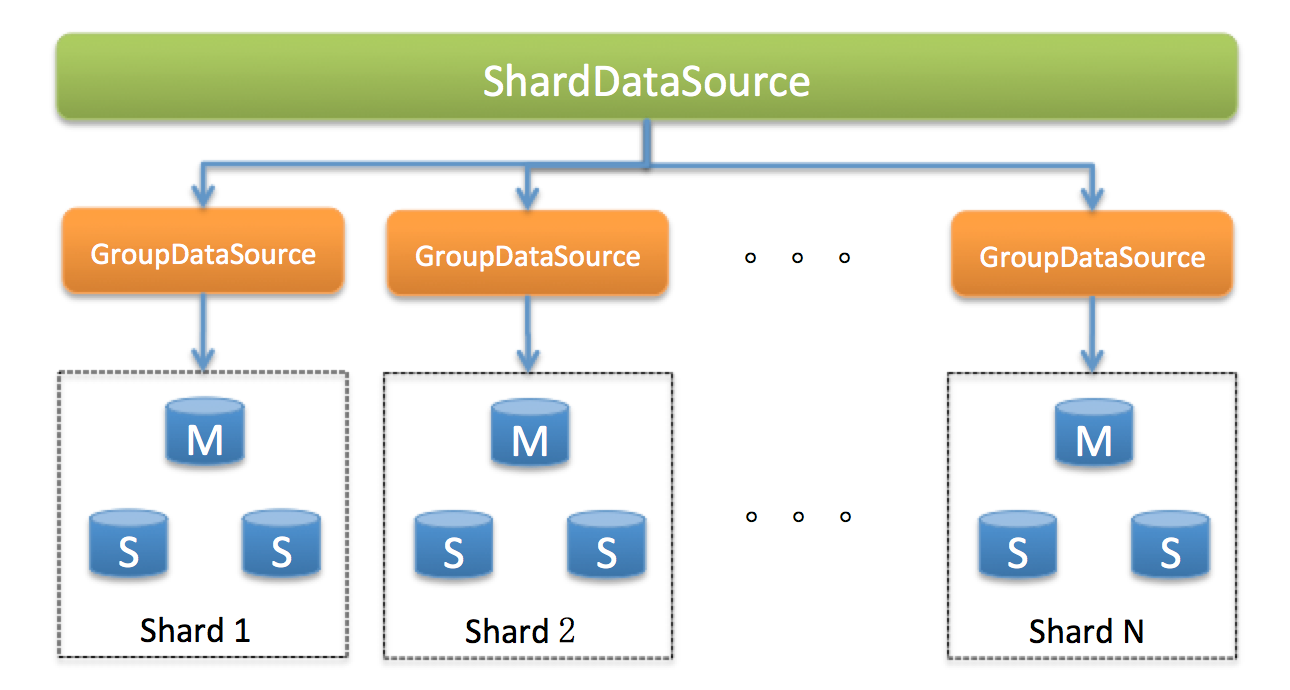
SingleDataSource
- 屏蔽底层DataSource的差异,通过C3p0DataSourceAdapter适配具体连接池配置,并根据配置创建指定类型的连接池。

GroupDataSource
GroupDataSource主要职能 读写分离、负载均衡与路由。但还有一个好处就是不需要写死配置(jdbcUrl、user|pwd、连接池配置,且配置修改可实时生效)。


读写分离策略: 官方文档: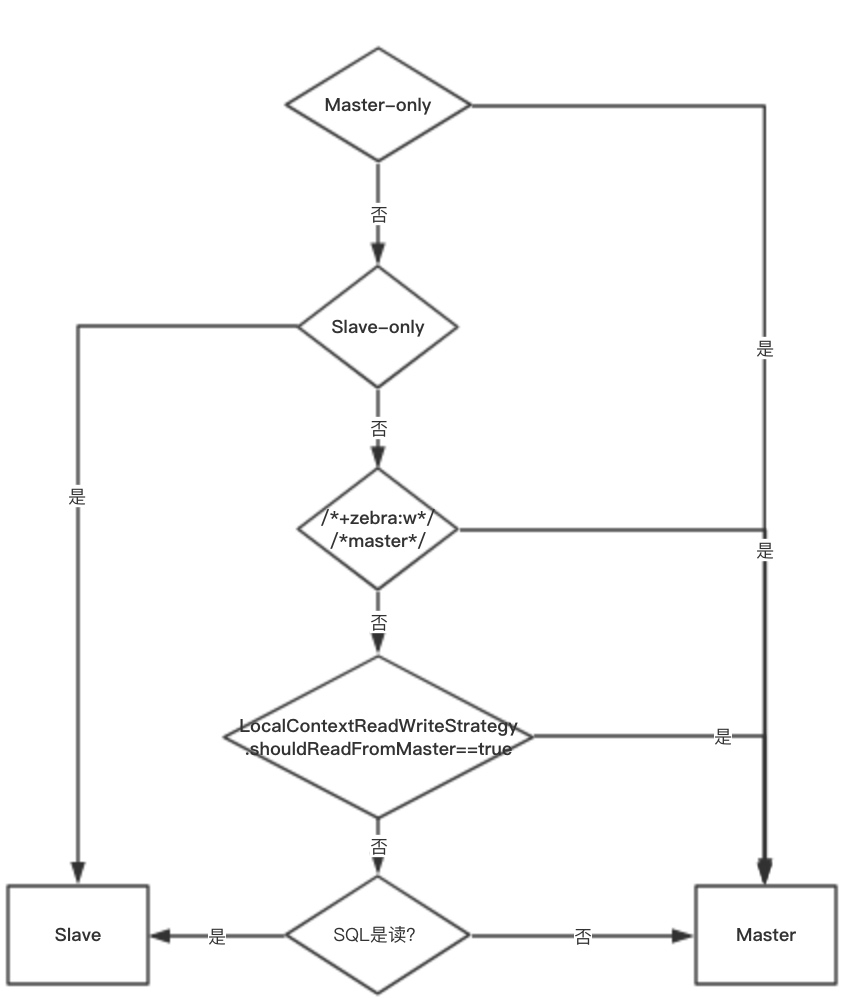
路由策略: 官方文档,见代码片段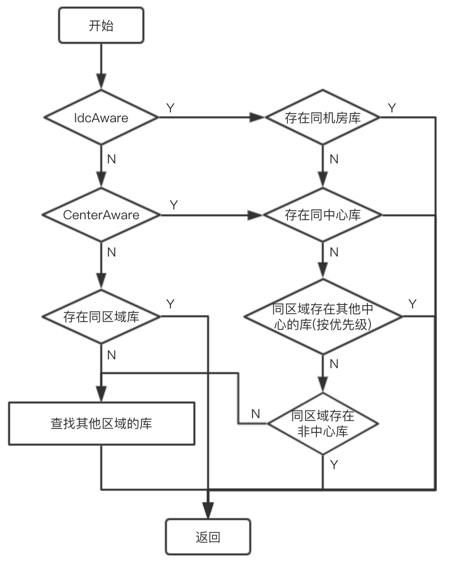
ShardDataSource
ShardDataSource的职责是支持分库分表路由,除此之外还有并发执行等。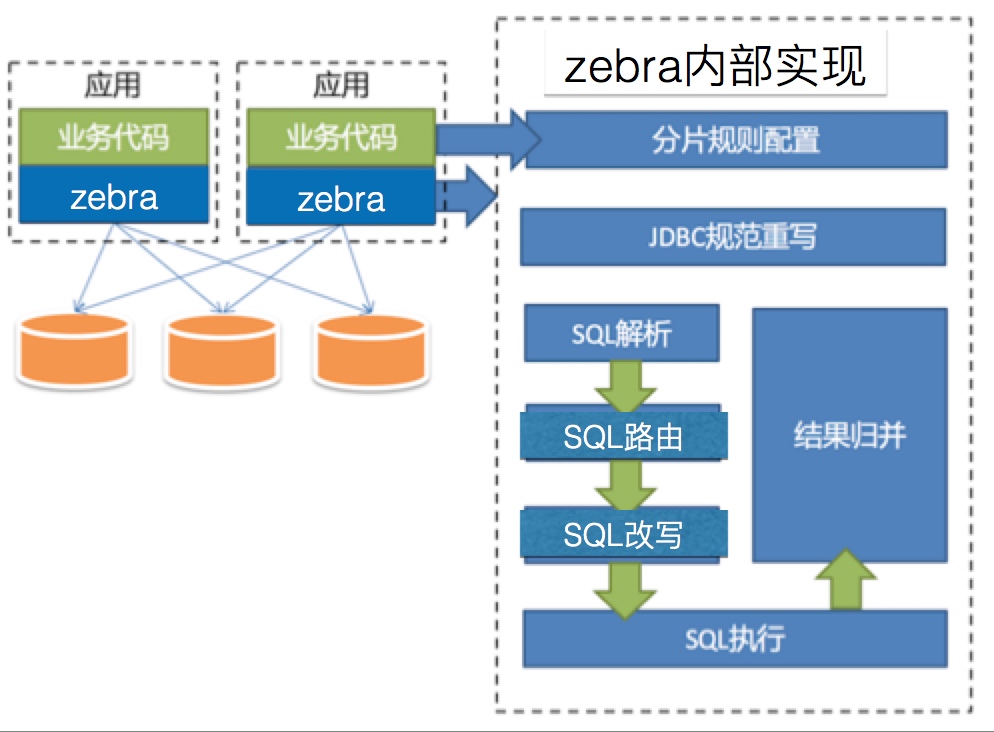
分片规则:
利用脚本语言的灵活性,支持任意维度的分片:支持HASH、时间等,同时也可以使用Groovy内置的函数
示例脚本:
1 | <shard-dimension dbRule="(#id#.intValue() % 8).intdiv(2)" |
SQL解析:利用
Druid的SqlParser解析SQL成语法树,能从中直接获取SQL类型、SQL表名、参数名、Hint等…,以此为基础进行路由分库分表
SQL路由: 根据SQL解析的结果以及配置的规则,通过运行规则运算脚本可以获得应该路由到哪个库的哪个表去执行。
SQL改写:结合SQL解析器解析的结果、SQL路由的结果改写SQL语句(重设表名)
并行执行:当路由结果需要到多个库的多张表中执行,则会使用线程池去并行执行结果并合并结果
结果合并: 客户端将多库返回的所有结果加载到内存,进行合并操作
Filter链(Filter-Chain模式、责任链模式)
Filter链是zebra实现可扩展性的机制。其作用相当于Spring AOP的Interceptor。
每个Filter可以在SQL执行的各个阶段起作用。比如getConnection、prepareStatement、executeSingleStatement。可以在Filter中实现监控连接池状态、SQL执行情况;改写SQL语句;改写SQL表名;SQL流控。

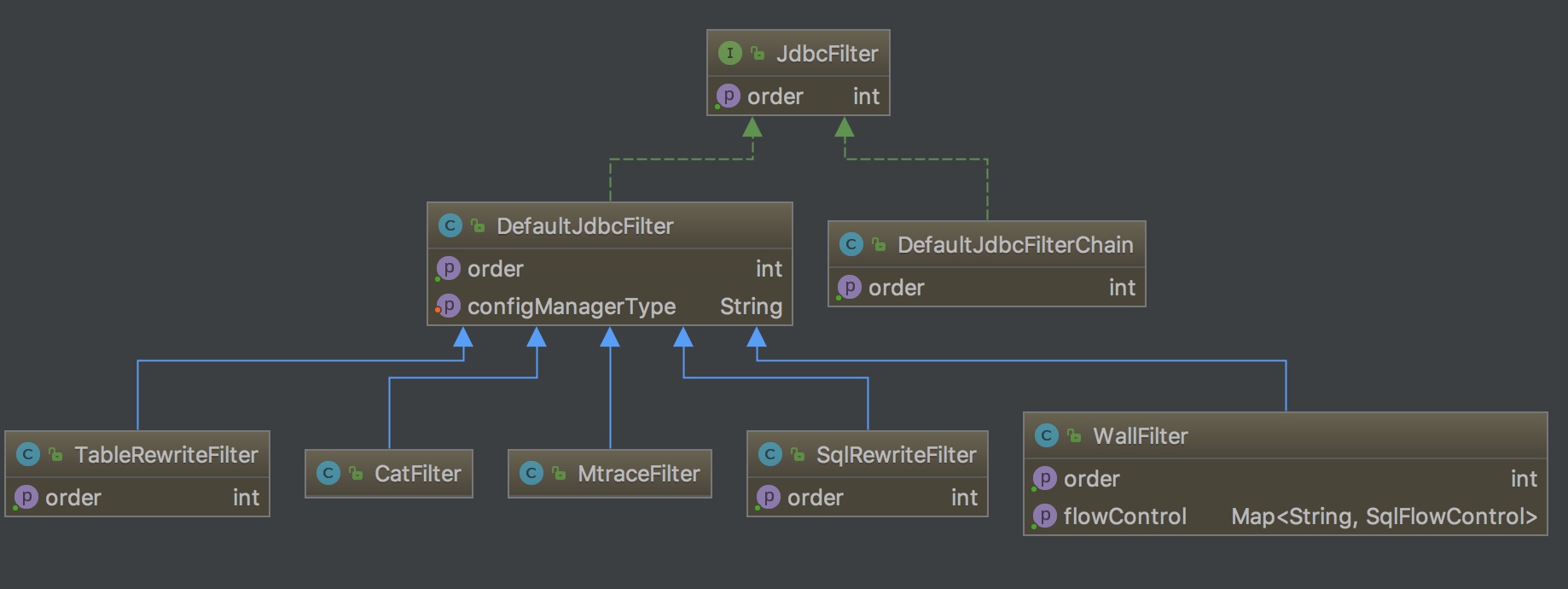
另外,业务方可以完全自行拓展Filter实现SQL执行统计、改写SQL等。(这里的MtraceFilter就是Mtrace的人员开发的。)
怎么拓展?
- 覆盖DefaultJdbcFilter,覆盖关注的SQL执行阶段对应的方法。
- 在META-INF中添加一个
zebra-filter.properties中记录需要加入到Filter链中的自定义Filter:
1 | =com.meituan.mtrace.zebra.filter.MtraceFilter |
zebra-dao
zebra-dao职责是异步化和物理分页。是在ORM框架MyBatis上做的一层封装。
异步化:MyBatis中对每个访问层接口,都会生成一个代理对象,每个代理对象对应的InvocationHandler为MapperProxy。
而zebra-dao是在MyBatis.MapperProxy的代理对象上加了又加了一层代理AsyncMapperProxy。在AsyncMapperProxy中实现异步化。
值得注意的是,这里异步化将请求放到线程池去执行,然后通过future.get()的形式,从IO模式上来说也只是阻塞模式,而不是NIO的方式;
另外,这里一个进程会共用一个线程池。
分页:
逻辑分页: 先从DB中拿出查询出来的所有的数据,而后再在内存中进行分页;
物理分页: 改写SQL,在SQL中加入分页部分的逻辑
limit 10,10。高级物理分页:不仅返回分页数据,同时也返回总数
zebra-dao实现分页的方式是实现MyBatis的Interceptor(PageInterceptor)。Interceptor是MyBatis的插件(另一种拓展性方式),通过它可以在MyBatis的执行过程中插入一些额外的逻辑。这里PageInterceptor主要是作用针对query方法。具体做法是:
- 改写SQL在尾部添加 limit x,x;
- 如果是高级物理分页,则会再进行一次
select count(*)查询,然后返回。
见源码片段
工作原理
zebra-api
GroupDataSource
GroupDataSource初始化时,会从配置平台读取所有数据库节点的配置信息。然后依据这些信息来创建两种类型的代理数据源d FailOverDataSource和LoadBalancedDataSource。其中,FailOverDataSource用来连接和管理主节点故障的拒绝写等。LoadBalancedDataSource则是用来连接所有从节点,并负责从节点读流量的路由。
读写策略
1 | LoadBalancedDataSource readDataSource; |
路由策略(针对读流量):
LoadBalanceDataSource中的router负责物理库和表的路由。
初始化时,会根据用户设置的配置信息(idcAware、..),创建路由
- 先将所有的数据库节点信息按是否与本地机器在同一个区域,分为两个集合
localRegionRouter、remoteRegionRouter; - 跟据配置的路由策略(
IdcAwareRouter、CenterWeightRouter、RegionAwareRouter)选择不同的实际路由器。 - (1) 如果设置的只是区域感知的话,则直接按权重路由
WeightDataSourceRouter - (2) 如果设置的是
CenterAware,则将选择的是CenterAwareRouter - (3) 如果设置的是
IdcAware,也是CenterAwareRouter,只是CenterAwareRouter中还有一个IdcAwareRouter
1 | public RegionAwareRouter(Map<String, DataSourceConfig> dataSourceConfigs, String configManagerType, |
ShardDataSource
分库分表原理
ShardDataSource中的DefaultShardRouter负责分库分表:
1 | //路由规则:根据分库分表规则和运行时参数,计算出应该到的库名和表名 |
执行路由的逻辑如下:
1 | public RouterResult router(final String sql, List<Object> params) throws ShardRouterException, ShardParseException { |
zebra-dao
异步化
MyBatis中每个DAO都对应一个MapperProxy,zebra-dao中则是AsyncMapperProxy。
1 | public class AsyncMapperProxy<T> implements InvocationHandler { |
分页 - PageInterceptor
1 | Object[] args = invocation.getArgs(); |
SQL解析与改写
Zebra在之前的版本中使用Antlr解析SQL,后来的版本替换成了Druid的 Sql Parser。Druid是个非常强大的工具,它支持达9种数据库类型SQL(db2|h2|mysql|hive|oracle…)。
这里我们以MySQL为例来介绍其SQL解析过程。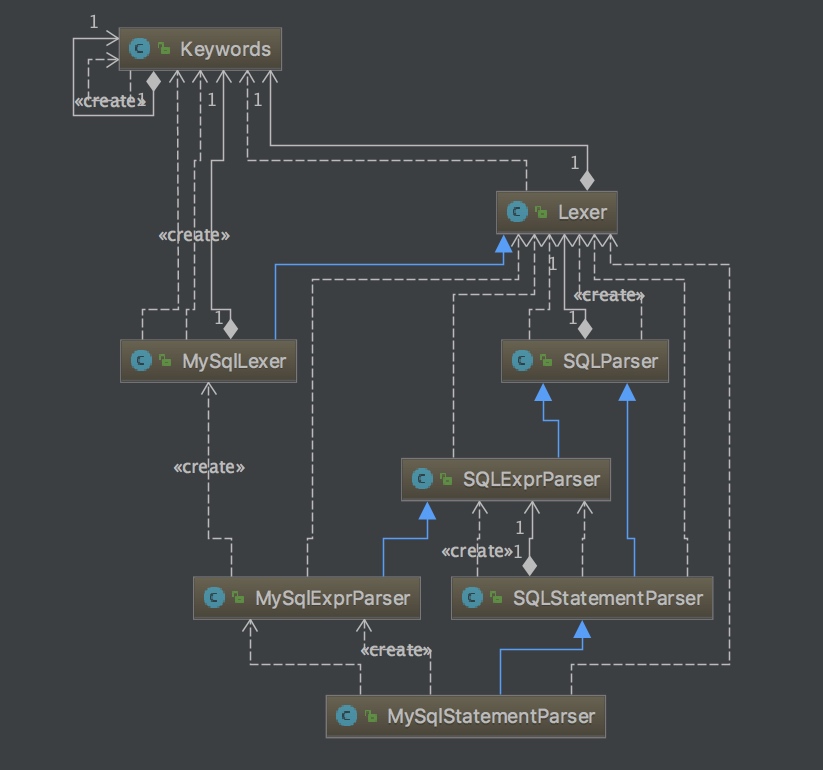
SQL的解析过程,分为词法分析和语法分析:
- 词法分析用来识别词汇,如关键字等。
Lexer就是用于词法分析的词法分析器。每个词法器都有自己的词汇库,KeyWords就是词汇库,且是所有数据库共用的词汇库。MySQLLexer是Lexer的子类。是用来专门解析MySQL的SQL语句。它的词汇库也在KeyWords加上了MySQL特有的关键字LIMIT、IDENTIFIED等; - 语法分析是在词法分析的基础上进行语法分析。生成一颗AST(
abstract syntax tree抽象语法树)。且其过程中也会判断用户的输入是否符合语法逻辑;
先来看一个词法分析的例子:
1 | String sql = "select * from order where cinema_id = 11 order by id, user_id"; |
其输出结果是:
1 | SELECT SELECT |
语法分析器在进行语法分析时,会根据词法分析器分析出的TOKEN、值来创建不同类型的节点,加到AST树中。
例如:
SELECT->SQLSelectOrder by->SQLOrderBy*->SQLSelectItem(每个结果集字段一个SQLSelectItem)FROM->SQLTableSource,SQLExprTableSource或者SQLSelect(嵌套查询)
以下面的例子来说明语法分析生成的结果:
1 | select id, name, movie_id from order where cinema_id = 11 order by id, user_id |
生成的语法树如下: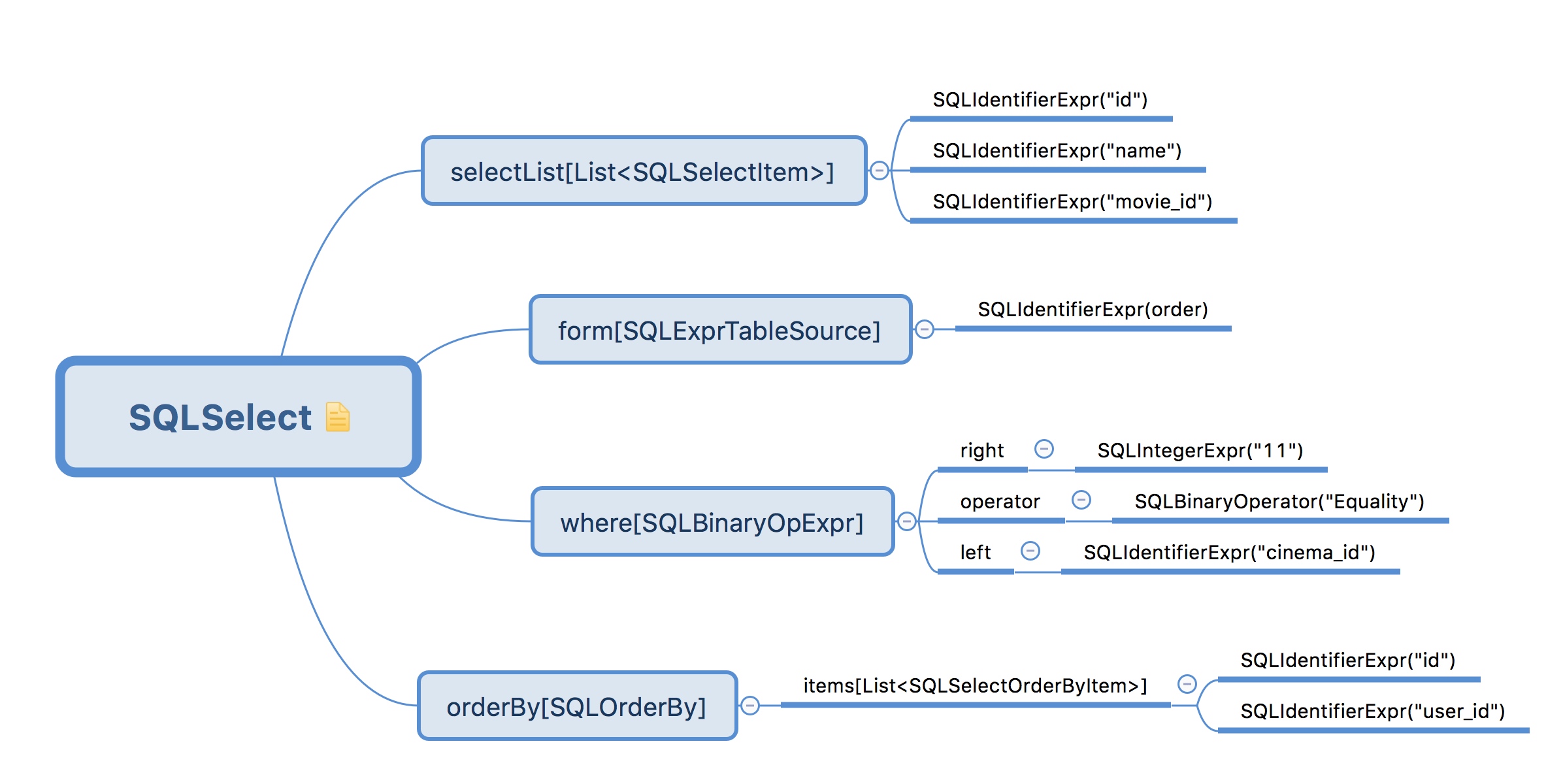
对AST树信息的访问,Druid定义一套接口SQLASTVisitor。业务方可以实现接口加入特定信息收集逻辑。调用SQLStatement.accept(visitor),visitor就会以类先序的顺序访问树上的所有节点。
下面给出一个自定义查找SQL中出现了哪些表名:
1 | public class TableNameASTVisitor implements MySqlASTVisitor { |
ShardRouter实现SQL改写的方式就是实现了一个Visitor-SimpleRewriteTableOutputVisitor,在其内部,将逻辑表名改写为路由后的物理表名:
1 | class SimpleRewriteTableOutputVisitor extends MySqlOutputVisitor { |

