2. 初始化过程
下面,将从客户端初始化和服务端初始化两个方面来讲解ZK的初始化过程:
客户端初始化
1 | public ZooKeeper(String connectString, int sessionTimeout, Watcher watcher, boolean canBeReadOnly, HostProvider aHostProvider, ZKClientConfig clientConfig) throws IOException { |
从上面可以看到最主要的即是 ClientCnxn,深入进去可以看到:
1 | public ClientCnxn(String chrootPath, HostProvider hostProvider, int sessionTimeout, ZooKeeper zooKeeper, |
SendThread是负责发送请求,而EventThread负责接收并处理事件。
ZK Client发送请求的过程是非常简单的:将请求进行包装成Packet,放进双向阻塞队列outgoingQueue中。然后SendThread不停地从其中拿出请求向Server发送请求。
其过程是在SendThread的run()方法中:
1 | public void run() { |
SendThread中不仅有调用clientCnxnSocket发送请求的逻辑,同时也维护着心跳逻辑,10秒内如果没有发送请求则发送一次心跳。
另外,值得一提的是,通过startConnect(serverAddress)完成与服务端的连接后,会触发一次sendThread.primeConnection(),它的作用是向服务端发起一次创建Session请求或者续联。另外,如果配置了zookeeper.disableAutoWatchReset = false会将本地的Watcher重新向连接的服务端注册一遍。
当服务端返回时,则由ClientCnxnSocketNetty.ZKClientHandler进行处理,而其最终会调用SendThread.readResponse。在readResponse会根据返回的内容进行相应处理。如果返回的Xid为-1时,表示事件通知,反序列化后触发相应的Wacther。
服务端初始化
服务端分为两种模式,单机模式和集群模式。后文重点介绍集群模式。
ZK中集群模式下,单实例启动类为QuorumPeerMain。
首先调用initializeAndRun进行配置参数解析,然后开启数据定时清理任务,定时删除过期的快照文件等;
其次调用runFromConfig方法,进行实例化QuorumPeer,并初始化其参数。最后调用QuorumPeer.start方法:
1 | public void runFromConfig(QuorumPeerConfig config) |
下面来重点看QuorumPeer的初始化过程:
1 | public synchronized void start() { |
其过程主要分为以下几步:
- 从快照文件中恢复原始数据,并读取 Epoch信息;
- 绑定端口,开始接收请求;
- 初始化选举算法,并初始化选举通讯组件;
- 运行
QuorumPeer.run方法启动服务:选举以及确定角色后提供服务。
对于 1 ,将在存储章节详细讲解。另外,因为选举算法是 ZK 的核心内容,也将另起一章进行介绍。下文将重点分析 选举的初始化工作以及选举后的服务器角色初始化工作。
首先来看选举初始化:
初始化过程会实例化类 QuorumCnxManager.Listener ,其会起一个 ServerSocekt 进行监听端口,接收其他 Participant 发给自己的选举相关请求。随后初始化FastLeaderElection对象,其内部会初始化两个阻塞队列sendqueue(发送队列)、recvqueue(接收队列)。同时实例化类Messenger,其内部会开启两个线程WorkerSender、WorkerReceiver,其工作原理如下:
- 发送:当选举算法中有发送请求时,会将请求放入
sendqueue中,而WorkerSender会从sendqueue中拉取请求,然后交给QuorumCnxManager。QuorumCnxManager按 sid 调用QuorumCnxManager将sendQueue队列中的发送请求ToSend按sid丢给queueSendMap.get(sid)对应的队列中,若服务器与sid之间没有创建连接则创建连接,并同时启动对应的RecvWorker和SendWorker,SendWorker从阻塞队列queueSendMap.get(sid)中获取请求进行socket发送; - 接收:刚介绍过
QuorumCnxManager的 RecvWroker 用于接收请求,将请求包装进阻塞队列recvQueue中,而后FastLeaderElection.WorkReceiver线程会从中取请求进行消费。
1 | protected Election createElectionAlgorithm(int electionAlgorithm) { |
初始化完选举算法后,服务开始正式启动运行。
服务启动开始时,是LOOKING状态。选举完成后就会变成OBSERVING|FOLLOWING|LEADING状态。
在LOOKING阶段,如果配置了readonlymode.enabled则在选举完成前开启只读服务ReadOnlyZooKeeperServer,当选举完成后卸载只读服务。
调用 makeLEStrategy().lookForLeader()开启选举。
1 | public void run() { |
当选举完成后,每个服务器就知道自己的角色,是OBSERVER、FOLLOWER还是LEADER。
Observer:当服务器角色是Observer时,其首先创建Observer以及ObserverZooKeeperServer,然后调用observeLeader与Leader建立连接。一开始发送OBSERVERINFO获取Leader的newLeaderZxid,然后开始与Leader的同步syncWithLeader,数据同步分为三种类型DIFF、SNAP、TUNC,具体后文将详细介绍。完成同步后,接收到Leader发来的UPTODATE命令,将ObserverZooKeeperServer与之前的ServerCnxnFactory绑定上(当有客户端请求来时,会将请求转发到ObserverZooKeeperServer,其他角色也是同样的道理)。最后调用xxZooKeeperServer.startup()建立起每个Server的处理器链路(每个角色最大差别即表现在处理器链上),具体见ZK角色介绍。Follower:其与Observer的过程大致相同,不同点在于一开始其向Leader发送的命令是Follwer。Leader:在创建Leader时,会开启一个SeverSocket,并监听端口接收请求。Leader.lead方法则开始初始化Leader,首先加载数据库,然后开启线程LearnerCnxAcceptor,接收来自Learner的请求。当接收到一半以上的NEWLEADER后才开始启动服务对外服务。一样也会调用LeaderZookeeperServer.startup建立起处理链。最后会开启一个ping服务,每两个tick一个周期。- 对于每个连接上来的
Learner,Leader都会创建一个LearnHandler。其负责与Learner间的交互。数据同步等。 - 初始化完成后,就开始接收
Learner发送的请求。
- 对于每个连接上来的
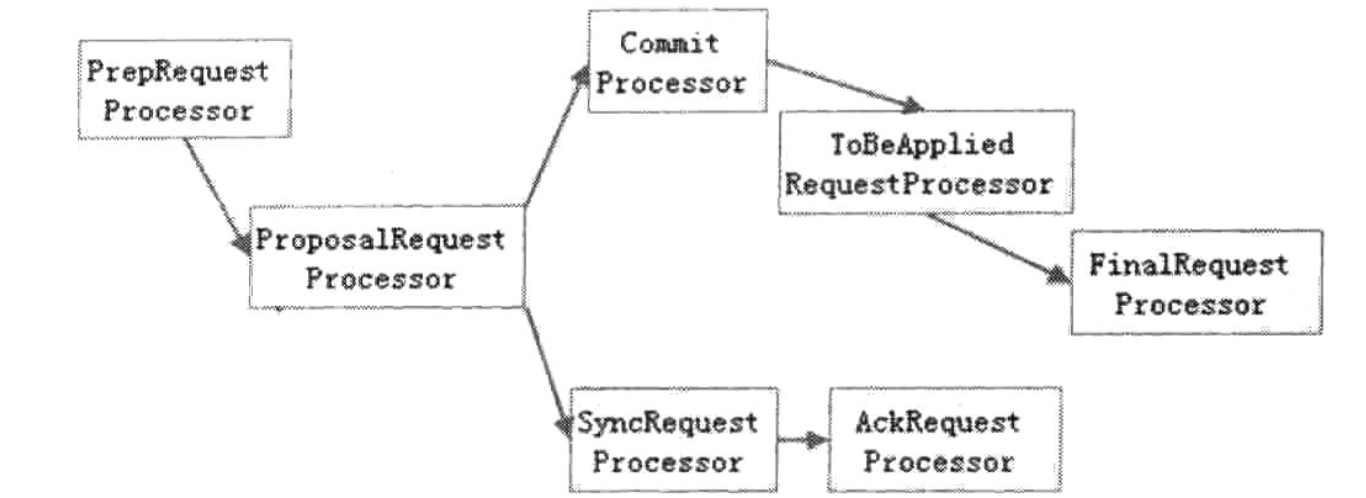
每个角色最大的不同即是其所对应的ZookeeperServer不同,而每个ZookeeperServer的本质不同在于其处理器链的不同。
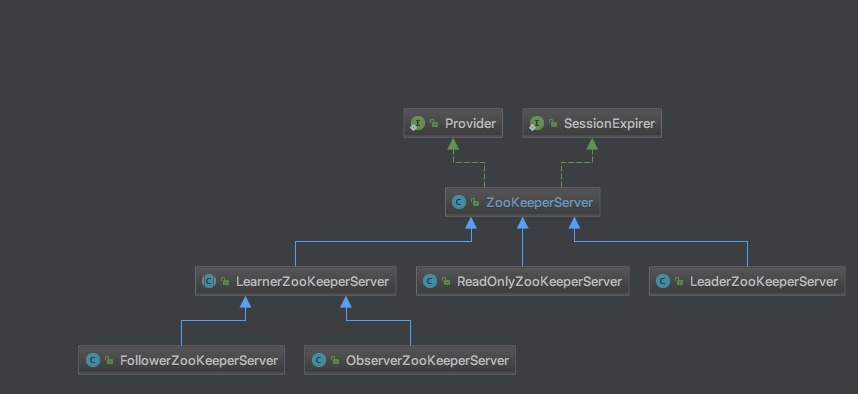
Leader的处理链:
Follower的处理链:
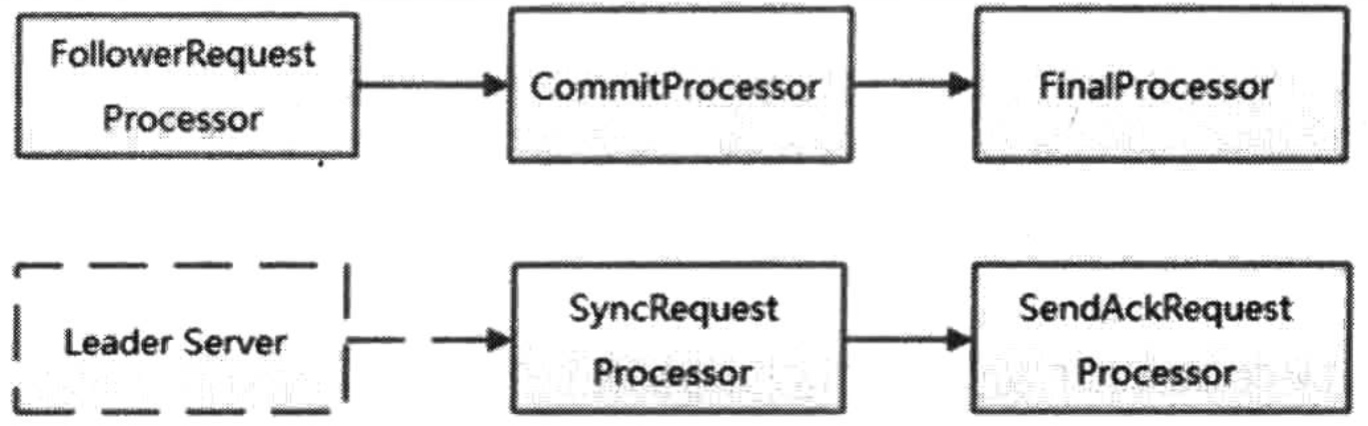
Observer的处理链
每个处理器的作用如下:

Reference:
- 《从Paxos到ZooKeeper 分布式一致性原理与实践》

